To get decimals points and vicevers
SELECT REGEXP_REPLACE('18.01', '(\d+)\.(\d+)', '\1') FROM dual;
SELECT REGEXP_REPLACE('18.0991', '(\d+)\.(\d+)', '\2') FROM dual;
For Credit-Card Number System
SELECT regexp_replace( :c, '[[:digit:]]{13,16}', 'X' ) r
FROM dual;
To get decimals points
select (18.9009-floor(18.9009))*power(10,length((18.9009-floor(18.9009)))-1) f from dual
or
SELECT REGEXP_REPLACE('18.9009', '(\d+)\.(\d+)', '\2') FROM dual;
Convert a name 'first middle last' into the 'last middle first' format
SELECT REGEXP_REPLACE('Hubert Horatio Hornblower','(.*) (.*) (.*)','\3 \2 \1') "Reformatted Name" FROM dual ;
To remove dollar sign
SELECT REGEXP_REPLACE('$1,234.56','\$',' ') FROM dual;
SELECT REGEXP_REPLACE('This is a test','t.+','XYZ') FROM dual;
SELECT REGEXP_REPLACE('Mississippi', 'si', 'SI', 1, 0, 'i') FROM dual;
Nov 24, 2009
ORA-00932: inconsistent datatypes
ORA-00932: inconsistent datatypes: expected - got CLOB
WHY THIS ERROR OCCURRING ?
WHEN WE EXECUTE THIS QUERY IT RESULTS TO AN ERROR (IE : ORA-00932)
SELECT TO_CLOB('DUMMY') FROM DUAL
UNION
SELECT TO_CLOB('DATA') FROM DUAL;
THIS ERROR CAN BE RESOLVED BY USING UNION ALL
EXAMPLE
SELECT TO_CLOB('DUMMY') FROM DUAL
UNION ALL
SELECT TO_CLOB('DATA') FROM DUAL;
WHY THIS ERROR OCCURRING ?
WHEN WE EXECUTE THIS QUERY IT RESULTS TO AN ERROR (IE : ORA-00932)
SELECT TO_CLOB('DUMMY') FROM DUAL
UNION
SELECT TO_CLOB('DATA') FROM DUAL;
THIS ERROR CAN BE RESOLVED BY USING UNION ALL
EXAMPLE
SELECT TO_CLOB('DUMMY') FROM DUAL
UNION ALL
SELECT TO_CLOB('DATA') FROM DUAL;
Sep 9, 2009
REGEXP 2
Contains alphabets
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:alpha:]]')
Contains only alphabets
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '^[[:alpha:]].*[[:alpha:]]$')
Contains enter character
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:cntrl:]]{1}')
OR
SELECT * FROM test WHERE testcol like '%'||chr(13)||'%'
-------------------------
Start with alphabets
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '^[[:alpha:]]')
Ends with alphabets
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:alpha:]]$')
Contains alphabets only with 5 and more characters
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:alpha:]]{5}')
Contains punctuations
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:punct:]]')
Contains space
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:space:]]')
To insert a space between the characters
SELECT testcol, REGEXP_REPLACE(testcol, '(.)', '\1 ') RES FROM test
To insert a hypen between every 4 characters
SELECT testcol, REGEXP_REPLACE(testcol, '(....)', '\1-') RES FROM test
To find third charactes with 'a'
SELECT testcol FROM test WHERE REGEXP_LIKE(testcol, '^..a.');
OR
SELECT testcol FROM test WHERE testcol LIKE '__a%'
To find the field having continous 3 spaces
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:space:]]{3}');
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:alpha:]]')
Contains only alphabets
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '^[[:alpha:]].*[[:alpha:]]$')
Contains enter character
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:cntrl:]]{1}')
OR
SELECT * FROM test WHERE testcol like '%'||chr(13)||'%'
-------------------------
Start with alphabets
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '^[[:alpha:]]')
Ends with alphabets
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:alpha:]]$')
Contains alphabets only with 5 and more characters
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:alpha:]]{5}')
Contains punctuations
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:punct:]]')
Contains space
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:space:]]')
To insert a space between the characters
SELECT testcol, REGEXP_REPLACE(testcol, '(.)', '\1 ') RES FROM test
To insert a hypen between every 4 characters
SELECT testcol, REGEXP_REPLACE(testcol, '(....)', '\1-') RES FROM test
To find third charactes with 'a'
SELECT testcol FROM test WHERE REGEXP_LIKE(testcol, '^..a.');
OR
SELECT testcol FROM test WHERE testcol LIKE '__a%'
To find the field having continous 3 spaces
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:space:]]{3}');
Jul 15, 2009
REGEXP 1
Find the position of try, trying, tried or tries
SELECT REGEXP_INSTR('We are trying to make the subject easier','tr(y(ing)?|(ied)|(ies))') RESULTNUM FROM dual;
To extract numbers
select regexp_substr('Oracle Database 10g is first grid database','[0-9]+') version from dual;
Following query places a space between Oracle its version
select regexp_replace('Oracle10g','([[:alpha:]])([[:digit:]]+.)','\1 \2') from dual;
Displays the starting position of one or more digits.
select regexp_instr('Oracle Database 10g is first grid aware database','[0-9]+') position from dual;
SELECT REGEXP_replace(TO_CHAR(sysdate, 'YYYY'), '^200[5-8]$','0') FROM dual
SELECT REGEXP_replace(TO_CHAR(sysdate, 'YYYY'), '^200[5-9]$','0') FROM dual
Only retreive data which contains digits
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:digit:]]');
To Remove Special Characters SELECT REGEXP_REPLACE('##$$$123&&!!__!','[^[:alnum:]'' '']', NULL) FROM dual; SELECT translate('##$$$1$$2#3&&!!__!', '[0-9]#$&&!_','[0-9]') FROM dual; SELECT translate('##$$$123&&!!__!', '0#$&&!_','0') FROM dual; FOR MORE REFERENCE OF REGEXP
SELECT REGEXP_INSTR('We are trying to make the subject easier','tr(y(ing)?|(ied)|(ies))') RESULTNUM FROM dual;
To extract numbers
select regexp_substr('Oracle Database 10g is first grid database','[0-9]+') version from dual;
Following query places a space between Oracle its version
select regexp_replace('Oracle10g','([[:alpha:]])([[:digit:]]+.)','\1 \2') from dual;
Displays the starting position of one or more digits.
select regexp_instr('Oracle Database 10g is first grid aware database','[0-9]+') position from dual;
SELECT REGEXP_replace(TO_CHAR(sysdate, 'YYYY'), '^200[5-8]$','0') FROM dual
SELECT REGEXP_replace(TO_CHAR(sysdate, 'YYYY'), '^200[5-9]$','0') FROM dual
Only retreive data which contains digits
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:digit:]]');
To Remove Special Characters SELECT REGEXP_REPLACE('##$$$123&&!!__!','[^[:alnum:]'' '']', NULL) FROM dual; SELECT translate('##$$$1$$2#3&&!!__!', '[0-9]#$&&!_','[0-9]') FROM dual; SELECT translate('##$$$123&&!!__!', '0#$&&!_','0') FROM dual; FOR MORE REFERENCE OF REGEXP
REGEXP
REGEXP_LIKE
SELECT * FROM scott.emp WHERE REGEXP_LIKE(ENAME,'FR') ;
OR
SELECT * FROM scott.emp WHERE ENAME LIKE '%FR%'
-------------------
SELECT testcol FROM test WHERE REGEXP_LIKE(testcol, '^Ste(v|ph)en$');
OR
SELECT testcol FROM test WHERE testcol like 'Steven%' or testcol like 'Stephen%'
parameters can be a combination of (Match Options)
* i: to match case insensitively
* c: to match case sensitively
* n: to make the dot (.) match new lines as well
* m: to make ^ and $ (Anchoring Characters) match beginning and end of a line in a multiline string
If you want all the entries that start with S, search for ^s
End with R, use r$
Start with S and end with H, use ^s.*h$
Start with S or end with R, use ^s|r$
All 4 letter names, use ^….$
Contains B, C, D or K, use [b-d,k]
All names with double letters, use (.)\1
Posix Characters
[:alnum:] Alphanumeric characters
[:alpha:] Alphabetic characters
[:blank:] Blank Space Characters
[:cntrl:] Control characters (nonprinting)
[:digit:] Numeric digits
[:graph:] Any [:punct:], [:upper:], [:lower:], and [:digit:] chars
[:lower:] Lowercase alphabetic characters
[:print:] Printable characters
[:punct:] Punctuation characters
[:space:] Space characters (nonprinting),such as carriage return,newline,vertical tab, and form feed
[:upper:] Uppercase alphabetic characters
[:xdigit:] Hexidecimal characters
Quantifier Characters
* Match 0 or more times
? Match 0 or 1 time
+ Match 1 or more times
{m} Match exactly m times
{m,} Match at least m times
{m, n} Match at least m times but no more than n times
\n Cause the previous expression to be repeated n times
Alternative Matching And Grouping Characters
| Separates alternates, often used with grouping operator ()
( ) Groups subexpression into a unit for alternations,for quantifiers,or for back referencing (see "Backreferences" section)
[char] Indicates a character list; most metacharacters inside a character list are understood as literals, with the exception of character classes, and the ^ and - meta characters
SELECT * FROM scott.emp WHERE REGEXP_LIKE(ENAME,'^FR$') ;
or
SELECT * FROM scott.emp WHERE ENAME LIKE 'FR'
SELECT REGEXP_REPLACE('FYICenter.com', '*.com','i') FROM DUAL;
or
SELECT REGEXP_REPLACE ('FYICenter.com', '^*.com$','i') FROM DUAL;
Here we search for strings that have either an "a", "c", or "f" as the second character of the string.
select REGEXP_REPLACE( 'paddy', '^.[acf]' ) from dual
SELECT REGEXP_REPLACE ('FYICenter.com', '^f.*$','i') FROM DUAL;
SELECT REGEXP_REPLACE ('FYICenter.com', '^Y.*$','i') FROM DUAL;
SELECT REGEXP_REPLACE ('FYICenter.com', '*Y.*$','i') FROM DUAL;
SELECT cust_email old_email,REGEXP_REPLACE(cust_email,'@.*\.COM','@BIRDS.COM') new_email FROM oe.customers;
SELECT REGEXP_REPLACE('H1234 H4321 H2345 H2345','(.*) (.*) (.*) (.*)','\4 ,\3, \2, \1')FROM dual;
SELECT * FROM scott.emp WHERE REGEXP_LIKE(ENAME,'FR') ;
OR
SELECT * FROM scott.emp WHERE ENAME LIKE '%FR%'
-------------------
SELECT testcol FROM test WHERE REGEXP_LIKE(testcol, '^Ste(v|ph)en$');
OR
SELECT testcol FROM test WHERE testcol like 'Steven%' or testcol like 'Stephen%'
parameters can be a combination of (Match Options)
* i: to match case insensitively
* c: to match case sensitively
* n: to make the dot (.) match new lines as well
* m: to make ^ and $ (Anchoring Characters) match beginning and end of a line in a multiline string
If you want all the entries that start with S, search for ^s
End with R, use r$
Start with S and end with H, use ^s.*h$
Start with S or end with R, use ^s|r$
All 4 letter names, use ^….$
Contains B, C, D or K, use [b-d,k]
All names with double letters, use (.)\1
Posix Characters
[:alnum:] Alphanumeric characters
[:alpha:] Alphabetic characters
[:blank:] Blank Space Characters
[:cntrl:] Control characters (nonprinting)
[:digit:] Numeric digits
[:graph:] Any [:punct:], [:upper:], [:lower:], and [:digit:] chars
[:lower:] Lowercase alphabetic characters
[:print:] Printable characters
[:punct:] Punctuation characters
[:space:] Space characters (nonprinting),such as carriage return,newline,vertical tab, and form feed
[:upper:] Uppercase alphabetic characters
[:xdigit:] Hexidecimal characters
Quantifier Characters
* Match 0 or more times
? Match 0 or 1 time
+ Match 1 or more times
{m} Match exactly m times
{m,} Match at least m times
{m, n} Match at least m times but no more than n times
\n Cause the previous expression to be repeated n times
Alternative Matching And Grouping Characters
| Separates alternates, often used with grouping operator ()
( ) Groups subexpression into a unit for alternations,for quantifiers,or for back referencing (see "Backreferences" section)
[char] Indicates a character list; most metacharacters inside a character list are understood as literals, with the exception of character classes, and the ^ and - meta characters
SELECT * FROM scott.emp WHERE REGEXP_LIKE(ENAME,'^FR$') ;
or
SELECT * FROM scott.emp WHERE ENAME LIKE 'FR'
SELECT REGEXP_REPLACE('FYICenter.com', '*.com','i') FROM DUAL;
or
SELECT REGEXP_REPLACE ('FYICenter.com', '^*.com$','i') FROM DUAL;
Here we search for strings that have either an "a", "c", or "f" as the second character of the string.
select REGEXP_REPLACE( 'paddy', '^.[acf]' ) from dual
SELECT REGEXP_REPLACE ('FYICenter.com', '^f.*$','i') FROM DUAL;
SELECT REGEXP_REPLACE ('FYICenter.com', '^Y.*$','i') FROM DUAL;
SELECT REGEXP_REPLACE ('FYICenter.com', '*Y.*$','i') FROM DUAL;
SELECT cust_email old_email,REGEXP_REPLACE(cust_email,'@.*\.COM','@BIRDS.COM') new_email FROM oe.customers;
SELECT REGEXP_REPLACE('H1234 H4321 H2345 H2345','(.*) (.*) (.*) (.*)','\4 ,\3, \2, \1')FROM dual;
Instead of Commit
Usually after a DML statement to make the change permenantly in the database we should execute commit statement .
Example
update scott.emp t where t.JOB='ff' where EMPNO=7654 ;
commit;
If we execute a DML statement and then DDL statement then without executing commit statement the effect of DML statement will save permenantly in the database
Example
update scott.emp t where t.JOB='ff' where EMPNO=7654 ;
create table test(test1 number);
Example
update scott.emp t where t.JOB='ff' where EMPNO=7654 ;
commit;
If we execute a DML statement and then DDL statement then without executing commit statement the effect of DML statement will save permenantly in the database
Example
update scott.emp t where t.JOB='ff' where EMPNO=7654 ;
create table test(test1 number);
May 29, 2009
Pinning in M/R // Background Process
Pinning stored procedure/function to shared pool in 11G
execute dbms_shared_pool.keep(owner.trigger, 'R');
---------------------------------------------
Script displays instance background process information. The script works when the database is MOUNTed or OPENed.
select A.SID,A.SERIAL#,A.PROGRAM,P.PID,P.SPID,A.OSUSER, /* Who Started INSTANCE */A.TERMINAL,
A.MACHINE,A.LOGON_TIME,B.NAME,B.Description,P.PGA_USED_MEM,P.PGA_FREEABLE_MEM,P.PGA_MAX_MEM
from v$session A,v$process P,v$bgprocess B where A.PADDR=B.PADDR AND A.PADDR=P.ADDR and
A.type='BACKGROUND';
execute dbms_shared_pool.keep(owner.trigger, 'R');
---------------------------------------------
Script displays instance background process information. The script works when the database is MOUNTed or OPENed.
select A.SID,A.SERIAL#,A.PROGRAM,P.PID,P.SPID,A.OSUSER, /* Who Started INSTANCE */A.TERMINAL,
A.MACHINE,A.LOGON_TIME,B.NAME,B.Description,P.PGA_USED_MEM,P.PGA_FREEABLE_MEM,P.PGA_MAX_MEM
from v$session A,v$process P,v$bgprocess B where A.PADDR=B.PADDR AND A.PADDR=P.ADDR and
A.type='BACKGROUND';
ESCAPE With LIKE Operator
ESCAPE With LIKE Operator
select ename from scott.emp where ename like '%_%';
But you will be surprised to see the results:
ENAME
------------
Will dispaly all Data in the Table
it is because _ is a wild card character. That is _ stands for any character. So the query yielded all the rows.
modified query to get the desired output as below:
select ename from scott.emp where ename like '%#_%' escape '#';
ENAME
------------
FRA_KLIN
select ename from scott.emp where ename like '%_%';
But you will be surprised to see the results:
ENAME
------------
Will dispaly all Data in the Table
it is because _ is a wild card character. That is _ stands for any character. So the query yielded all the rows.
modified query to get the desired output as below:
select ename from scott.emp where ename like '%#_%' escape '#';
ENAME
------------
FRA_KLIN
May 28, 2009
About TNS file
What is PRESENTATION=RO in tnsnames.ora file
Check the entry in tnsnames.ora file:
EXTPROC_CONNECTION_DATA =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1))
)
(CONNECT_DATA =
(SID = PLSExtProc)
(PRESENTATION = RO)
)
)
In this article we will be discussing about the PRESENTATION clause in the entry.
Little history
The whole tnsnames.ora file is meant to be information for client softwares which will be connecting to the Oracle server (database).
The client must know where the database resides, which PROTOCOL to use for connection, unique identifier of the database etc.
Back to EXTPROC_CONNECTION_DATA
But in this particular tnsnames.ora entry, Oracle uses this for connecting to external procedures. The examples of external procedures are the procedures written in C/C++/VB which are compiled as available as shared libraries (DLLs).
PRESENTATION in connect descriptor
There must be a presentation layer between client and server, if in case the charactersets of both are different. This layer ensures that information sent from within application layer of one system is readable by application layer of the other system.
The various presentation layer options available are
1. Two-Task Common (TTC)
2. JavaTTC
3. FTP
4. HTTP
5. GIOP (for IIOP)
6. IMAP
7. POP
8. IM APSSL (6, 7, and 8 are for email) etc
9. RO
TTC
TTC/Two-Task Common is Oracle's implementation of presentation layer. It provides characterset and datatype conversion between different charactersets or formats on the client and server. This layer is optimized on a per connection basis to perform conversion only when required.
JavaTTC
This is a Java implementation of TTC for Oracle Net foundation layer capable of providing characterset and datatype conversion.
It is responsible for
a. Negotiating protocol version and datatype
b. Determining any conversions
c. SQL statement execution
RO
For external procedures the PRESENTATION layer value will be normally RO, meaning for "Remote Operation". By this parameter the application layer knows that a remote procedure call (RPC) has to be made.
Check the entry in tnsnames.ora file:
EXTPROC_CONNECTION_DATA =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1))
)
(CONNECT_DATA =
(SID = PLSExtProc)
(PRESENTATION = RO)
)
)
In this article we will be discussing about the PRESENTATION clause in the entry.
Little history
The whole tnsnames.ora file is meant to be information for client softwares which will be connecting to the Oracle server (database).
The client must know where the database resides, which PROTOCOL to use for connection, unique identifier of the database etc.
Back to EXTPROC_CONNECTION_DATA
But in this particular tnsnames.ora entry, Oracle uses this for connecting to external procedures. The examples of external procedures are the procedures written in C/C++/VB which are compiled as available as shared libraries (DLLs).
PRESENTATION in connect descriptor
There must be a presentation layer between client and server, if in case the charactersets of both are different. This layer ensures that information sent from within application layer of one system is readable by application layer of the other system.
The various presentation layer options available are
1. Two-Task Common (TTC)
2. JavaTTC
3. FTP
4. HTTP
5. GIOP (for IIOP)
6. IMAP
7. POP
8. IM APSSL (6, 7, and 8 are for email) etc
9. RO
TTC
TTC/Two-Task Common is Oracle's implementation of presentation layer. It provides characterset and datatype conversion between different charactersets or formats on the client and server. This layer is optimized on a per connection basis to perform conversion only when required.
JavaTTC
This is a Java implementation of TTC for Oracle Net foundation layer capable of providing characterset and datatype conversion.
It is responsible for
a. Negotiating protocol version and datatype
b. Determining any conversions
c. SQL statement execution
RO
For external procedures the PRESENTATION layer value will be normally RO, meaning for "Remote Operation". By this parameter the application layer knows that a remote procedure call (RPC) has to be made.
Benefit of Cursor For loop for 10g
Which will run much slower than the other two, and why?
a.
DECLARE
CURSOR employees_cur IS SELECT * FROM employees;
BEGIN
FOR employee_rec IN employees_cur LOOP
do_stuff (employee_rec);
END LOOP;
END;
b.
DECLARE
CURSOR employees_cur IS SELECT * FROM employees;
l_employee employees%ROWTYPE;
BEGIN
OPEN employees_cur;
LOOP
FETCH employees_cur INTO l_employee;
EXIT WHEN employees_cur%NOTFOUND;
do_stuff (l_employee);
END LOOP;
CLOSE employees_cur;
END;
c.
DECLARE
CURSOR employees_cur IS SELECT * FROM employees;
TYPE employees_aat IS TABLE OF employees%ROWTYPE INDEX BY PLS_INTEGER;
l_employees employees_aat;
BEGIN
OPEN employees_cur;
LOOP
FETCH employees_cur
BULK COLLECT INTO l_employees LIMIT 100;
EXIT WHEN l_employees.COUNT () = 0;
FOR indx IN 1 .. l_employees.COUNT
LOOP
do_stuff (l_employees (indx));
END LOOP;
END LOOP;
CLOSE employees_cur;
END;
(b) Is the slowest. That's because on Oracle 10g and higher, the PL/SQL optimizer will automatically rewrite cursor FOR loops so that they are executed in the same way as the BULK COLLECT query.
a.
DECLARE
CURSOR employees_cur IS SELECT * FROM employees;
BEGIN
FOR employee_rec IN employees_cur LOOP
do_stuff (employee_rec);
END LOOP;
END;
b.
DECLARE
CURSOR employees_cur IS SELECT * FROM employees;
l_employee employees%ROWTYPE;
BEGIN
OPEN employees_cur;
LOOP
FETCH employees_cur INTO l_employee;
EXIT WHEN employees_cur%NOTFOUND;
do_stuff (l_employee);
END LOOP;
CLOSE employees_cur;
END;
c.
DECLARE
CURSOR employees_cur IS SELECT * FROM employees;
TYPE employees_aat IS TABLE OF employees%ROWTYPE INDEX BY PLS_INTEGER;
l_employees employees_aat;
BEGIN
OPEN employees_cur;
LOOP
FETCH employees_cur
BULK COLLECT INTO l_employees LIMIT 100;
EXIT WHEN l_employees.COUNT () = 0;
FOR indx IN 1 .. l_employees.COUNT
LOOP
do_stuff (l_employees (indx));
END LOOP;
END LOOP;
CLOSE employees_cur;
END;
(b) Is the slowest. That's because on Oracle 10g and higher, the PL/SQL optimizer will automatically rewrite cursor FOR loops so that they are executed in the same way as the BULK COLLECT query.
Tuning the LIKE-clause
Tuning the LIKE-clause (by using reverse key indexes)
For tuning Like operator (like '%SON') is to create a REVERSE index - and then programmatically reverse the LIKE-clause to read LIKE 'NOS%'
Steps:
CREATE INDEX Cust_Name_reverese_idx
ON customer(Cust_Name) REVERSE;
2. Programmatically reverse the SQL LIKE-clause to read '%saliV%':
SELECT * FROM customer WHERE Cust_Name LIKE '%Vilas%'
New Query:
SELECT * FROM customer WHERE Cust_Name LIKE '%saliV%';
For tuning Like operator (like '%SON') is to create a REVERSE index - and then programmatically reverse the LIKE-clause to read LIKE 'NOS%'
Steps:
CREATE INDEX Cust_Name_reverese_idx
ON customer(Cust_Name) REVERSE;
2. Programmatically reverse the SQL LIKE-clause to read '%saliV%':
SELECT * FROM customer WHERE Cust_Name LIKE '%Vilas%'
New Query:
SELECT * FROM customer WHERE Cust_Name LIKE '%saliV%';
Quote Operator
select 'Oracle''s web blog. It''s personal.' str from dual;
By Q - quote operator the above statement can also be represented as any one of the below.
Different ways to Use Quote Operator.
select q'(Oracle's web blog. It's personal.)' str from dual;
select q'[Oracle's web blog. It's personal.]' str from dual;
select q'Oracle's web blog. It's personal.A' str from dual;
select q'/Oracle's web blog. It's personal./' str from dual;
select q'ZOracle's web blog. It's personal.Z' str from dual;
select q'|Oracle's web blog. It's personal.|' str from dual;
select q'+Oracle's web blog. It's personal.+' str from dual;
select q'zOracle's web blog. It's personal.z' str from dual;
By Q - quote operator the above statement can also be represented as any one of the below.
Different ways to Use Quote Operator.
select q'(Oracle's web blog. It's personal.)' str from dual;
select q'[Oracle's web blog. It's personal.]' str from dual;
select q'Oracle's web blog. It's personal.A' str from dual;
select q'/Oracle's web blog. It's personal./' str from dual;
select q'ZOracle's web blog. It's personal.Z' str from dual;
select q'|Oracle's web blog. It's personal.|' str from dual;
select q'+Oracle's web blog. It's personal.+' str from dual;
select q'zOracle's web blog. It's personal.z' str from dual;
Locks , Dummy Table
To get the locks on an object
SELECT oracle_username USERNAME,owner OBJECT_OWNER,object_name, object_type, s.osuser,s.SID SID,s.SERIAL# SERIAL,DECODE(l.block,
0, 'Not Blocking', 1, 'Blocking', 2, 'Global') STATUS, DECODE(v.locked_mode, 0, 'None', 1, 'Null', 2, 'Row-S (SS)', 3, 'Row-X (SX)', 4, 'Share', 5, 'S/Row-X (SSX)', 6, 'Exclusive', TO_CHAR(lmode) ) MODE_HELD
FROM gv$locked_object v, dba_objects d,gv$lock l, gv$session s WHERE v.object_id = d.object_id AND (v.object_id = l.id1) and v.session_id = s.sid ORDER BY oracle_username, session_id;
-------------------------------------------------------------
To create our own much faster DUMMY Table
CREATE TABLE MYDUAL(DUMMY VARCHAR2(1) PRIMARY KEY CONSTRAINT ONE_ROW
CHECK(DUMMY='X')) ORGANIZATION INDEX;
SELECT oracle_username USERNAME,owner OBJECT_OWNER,object_name, object_type, s.osuser,s.SID SID,s.SERIAL# SERIAL,DECODE(l.block,
0, 'Not Blocking', 1, 'Blocking', 2, 'Global') STATUS, DECODE(v.locked_mode, 0, 'None', 1, 'Null', 2, 'Row-S (SS)', 3, 'Row-X (SX)', 4, 'Share', 5, 'S/Row-X (SSX)', 6, 'Exclusive', TO_CHAR(lmode) ) MODE_HELD
FROM gv$locked_object v, dba_objects d,gv$lock l, gv$session s WHERE v.object_id = d.object_id AND (v.object_id = l.id1) and v.session_id = s.sid ORDER BY oracle_username, session_id;
-------------------------------------------------------------
To create our own much faster DUMMY Table
CREATE TABLE MYDUAL(DUMMY VARCHAR2(1) PRIMARY KEY CONSTRAINT ONE_ROW
CHECK(DUMMY='X')) ORGANIZATION INDEX;
Database vs Data warehouse
Similarities in Database and Data warehouse:
* Both database and data warehouse are databases.
* Both database and data warehouse have some tables containing data.
* Both database and data warehouse have indexes, keys, views etc.
Differences
* The Application database is not your Data Warehouse for the simple reason that your application database is never designed to answer queries.
* The database is designed and optimized to record while the data warehouse is designed and optimized to respond to analysis questions that are critical for your business.
* Application databases are On-Line Transaction processing systems where every transition has to be recorded, and super-fast at that.
* A Data Warehouse on the other hand is a database that is designed for facilitating querying and analysis
* A data warehouse is designed as On-Line Analytical processing systems . A data warehouse contains read-only data that can be queried and analyzed far more efficiently as compared to regular OLTP application databases. In this sense an OLAP system is designed to be read-optimized.
* Separation from your application database also ensures that your business intelligence solution is scalable, better documented and managed and can answer questions far more efficiently and frequently.
Data warehouse is better than a database:
The Data Warehouse is the foundation of any analytics initiative. You take data from various data sources in the organization, clean and pre-process it to fit business needs, and then load it into the data warehouse for everyone to use. This process is called ETL which stands for ‘Extract, transform, and load'.
Suppose you are running your reports off the main application database. Now the question is would the solution still work next year with 20% more customers, 50% more business, 70% more users, and 300% more reports? What about the year after next? If you are sure that your solution will run without any changes, great!! However, if you have already budgeted to buy new state-of-the-art hardware and 25 new Oracle licenses with those partition-options and the 33 other cool-sounding features, you might consider calling up Oracle and letting them know. There's a good chance they'd make you their brand ambassador.
Creation of a data warehouse leads to a direct increase in quality of analyses as you can keep only the needed information in simpler tables, standardized, and denormalized to reduce the linkages between tables and the corresponding complexity of queries.
A data warehouse drastically reduces the cost-per-analysis and thus permits more analysis per FTE.
(Data Adopted)
* Both database and data warehouse are databases.
* Both database and data warehouse have some tables containing data.
* Both database and data warehouse have indexes, keys, views etc.
Differences
* The Application database is not your Data Warehouse for the simple reason that your application database is never designed to answer queries.
* The database is designed and optimized to record while the data warehouse is designed and optimized to respond to analysis questions that are critical for your business.
* Application databases are On-Line Transaction processing systems where every transition has to be recorded, and super-fast at that.
* A Data Warehouse on the other hand is a database that is designed for facilitating querying and analysis
* A data warehouse is designed as On-Line Analytical processing systems . A data warehouse contains read-only data that can be queried and analyzed far more efficiently as compared to regular OLTP application databases. In this sense an OLAP system is designed to be read-optimized.
* Separation from your application database also ensures that your business intelligence solution is scalable, better documented and managed and can answer questions far more efficiently and frequently.
Data warehouse is better than a database:
The Data Warehouse is the foundation of any analytics initiative. You take data from various data sources in the organization, clean and pre-process it to fit business needs, and then load it into the data warehouse for everyone to use. This process is called ETL which stands for ‘Extract, transform, and load'.
Suppose you are running your reports off the main application database. Now the question is would the solution still work next year with 20% more customers, 50% more business, 70% more users, and 300% more reports? What about the year after next? If you are sure that your solution will run without any changes, great!! However, if you have already budgeted to buy new state-of-the-art hardware and 25 new Oracle licenses with those partition-options and the 33 other cool-sounding features, you might consider calling up Oracle and letting them know. There's a good chance they'd make you their brand ambassador.
Creation of a data warehouse leads to a direct increase in quality of analyses as you can keep only the needed information in simpler tables, standardized, and denormalized to reduce the linkages between tables and the corresponding complexity of queries.
A data warehouse drastically reduces the cost-per-analysis and thus permits more analysis per FTE.
(Data Adopted)
Check Constraint
Check Constraint
CREATE TABLE EMP_DETAILS(
NAME VARCHAR2(20),
MARITAL CHAR(1) CHECK(MARITAL='S' OR MARITAL = 'M'),
CHILDREN NUMBER,
CHECK((MARITAL = 'S' AND CHILDREN=0) OR
(MARITAL = 'M' AND CHILDREN >=0)));
This constraint can only be kept at table level because it accesses more than one field. Now the valid values for CHILDREN field is based on MARITAL field. MARITAL is also one of 'S' or 'M'. If the field MARITAL is 'S' it will only allow 0 as a valid value. If the MARITAL field is 'M' it will allow either 0 or a value greater than 0.
CREATE TABLE EMP_DETAILS(
NAME VARCHAR2(20),
MARITAL CHAR(1) CHECK(MARITAL='S' OR MARITAL = 'M'),
CHILDREN NUMBER,
CHECK((MARITAL = 'S' AND CHILDREN=0) OR
(MARITAL = 'M' AND CHILDREN >=0)));
This constraint can only be kept at table level because it accesses more than one field. Now the valid values for CHILDREN field is based on MARITAL field. MARITAL is also one of 'S' or 'M'. If the field MARITAL is 'S' it will only allow 0 as a valid value. If the MARITAL field is 'M' it will allow either 0 or a value greater than 0.
Some Good Queries
To get size of a table
select segment_name table_name,sum(bytes)/(1024*1024) table_size_meg
from user_extents where segment_type='TABLE'
and segment_name = 'EMP_MAST' group by segment_name
---------------------------------------------------------------
To Select only unlocked rows
select * from emp_MAST for update skip locked;
CHECK THIS USING TWO SQL PLUS AND SESSION BROWSER IN TOAD
UPDATE EMP_MAST SET ENAME='p' WHERE EMPNO=7369 ; (IN FIRST SQLPLUS DONT EXECUTE COMMIT )
select * from emp_MAST for update skip locked; (IN SECOND SQLPLUS)
--------------------------------------------------------
To get numbers of records in all tables in a Schema
select table_name,to_number(extractvalue(xmltype(
dbms_xmlgen.getxml('select count(*) c from '||table_name)
),'/ROWSET/ROW/C')) count from user_tables order by 1
---------------------------------------------------------
To generate a CSV output of a Table
select regexp_replace(column_value,' *<[^>]*>[^>]*>',';')
from table(xmlsequence(cursor(select * from EMP_MAST)));
--------------------------------------------------------------
To get Version and login naem
select OLAPSYS.version,sys.LOGIN_USER from dual
--------------------------------------------------
select APEX_UTIL.get_since(sysdate-10) /* get how many days ago */,APEX_UTIL.url_encode('http://www.oracle4u.com') from dual;
-------------------------------------------
select round(12.55555E78,2) from dual ---- For numeric overflow round function will not work
------------------------------------------
How to do pattern search in a subquery using LIKE
with dt as( select distinct BOTTLETYPE from DRINKS WHERE BOTTLETYPE is not null )
select * from tabled,dt where name like ''||dt.BOTTLETYPE||'%' order by 2
OR
select * from tabled df,(select distinct BOTTLETYPE from DRINKS WHERE BOTTLETYPE is not null) gh where name like ''||gh.BOTTLETYPE||'%' order by 2
OR
SELECT * FROM tabled df WHERE EXISTS (SELECT distinct BOTTLETYPE FROM DRINKS gh WHERE BOTTLETYPE is not null and df.name LIKE ''||gh.BOTTLETYPE||'%') ;
----------------
Check for hidden database user ----------------
Run OS Commands via PLSQL ----------------
Run OS Commands via DBMS_SCHEDULER ----------------
Run OS Commands via Create Table --------------------------------
select segment_name table_name,sum(bytes)/(1024*1024) table_size_meg
from user_extents where segment_type='TABLE'
and segment_name = 'EMP_MAST' group by segment_name
---------------------------------------------------------------
To Select only unlocked rows
select * from emp_MAST for update skip locked;
CHECK THIS USING TWO SQL PLUS AND SESSION BROWSER IN TOAD
UPDATE EMP_MAST SET ENAME='p' WHERE EMPNO=7369 ; (IN FIRST SQLPLUS DONT EXECUTE COMMIT )
select * from emp_MAST for update skip locked; (IN SECOND SQLPLUS)
--------------------------------------------------------
To get numbers of records in all tables in a Schema
select table_name,to_number(extractvalue(xmltype(
dbms_xmlgen.getxml('select count(*) c from '||table_name)
),'/ROWSET/ROW/C')) count from user_tables order by 1
---------------------------------------------------------
To generate a CSV output of a Table
select regexp_replace(column_value,' *<[^>]*>[^>]*>',';')
from table(xmlsequence(cursor(select * from EMP_MAST)));
--------------------------------------------------------------
To get Version and login naem
select OLAPSYS.version,sys.LOGIN_USER from dual
--------------------------------------------------
select APEX_UTIL.get_since(sysdate-10) /* get how many days ago */,APEX_UTIL.url_encode('http://www.oracle4u.com') from dual;
-------------------------------------------
select round(12.55555E78,2) from dual ---- For numeric overflow round function will not work
------------------------------------------
How to do pattern search in a subquery using LIKE
with dt as( select distinct BOTTLETYPE from DRINKS WHERE BOTTLETYPE is not null )
select * from tabled,dt where name like ''||dt.BOTTLETYPE||'%' order by 2
OR
select * from tabled df,(select distinct BOTTLETYPE from DRINKS WHERE BOTTLETYPE is not null) gh where name like ''||gh.BOTTLETYPE||'%' order by 2
OR
SELECT * FROM tabled df WHERE EXISTS (SELECT distinct BOTTLETYPE FROM DRINKS gh WHERE BOTTLETYPE is not null and df.name LIKE ''||gh.BOTTLETYPE||'%') ;
----------------
Check for hidden database user ----------------
Run OS Commands via PLSQL ----------------
Run OS Commands via DBMS_SCHEDULER ----------------
Run OS Commands via Create Table --------------------------------
May 25, 2009
Much More About Constraints
PRIMARY KEY LOOK UP DURING FOREIGN KEY CREATION
The lookup of matching primary keys at time of foreign key insertion takes time.In realease Oracle 9i , the first 256 primary keys can be cached so the addition of multiple foreign keys become significantly faster .The cache is only set up after the second row is processed.this avoid overhead of setting up a cache for single row DML.
----------------------
Constraints On View
--------------------
Constraint definitions are done on View from Oracle 9i onwards.
Views constraint definitions are declarative in nature;therefore DML operations on view are subject to the constraints defined on base tables.
defining constraints on base table is necessary ,not only for data correctness and cleanliness but also for MV query
NOT NULL and CHECK constraint are not supported on Views
For Creating View with constraints you must specify [RELY|NORELY ](Allows/disallows query rewrites) DISABLE NOVALIDATE (valid state for view constraint )
Otherwise it will result an error message.
The lookup of matching primary keys at time of foreign key insertion takes time.In realease Oracle 9i , the first 256 primary keys can be cached so the addition of multiple foreign keys become significantly faster .The cache is only set up after the second row is processed.this avoid overhead of setting up a cache for single row DML.
----------------------
Constraints On View
--------------------
Constraint definitions are done on View from Oracle 9i onwards.
Views constraint definitions are declarative in nature;therefore DML operations on view are subject to the constraints defined on base tables.
defining constraints on base table is necessary ,not only for data correctness and cleanliness but also for MV query
NOT NULL and CHECK constraint are not supported on Views
For Creating View with constraints you must specify [RELY|NORELY ](Allows/disallows query rewrites) DISABLE NOVALIDATE (valid state for view constraint )
Otherwise it will result an error message.
May 21, 2009
Trigger (Insertion on Same Table)
Trigger to insert a field from sequence at user insertion itself by avoiding mutating table error. For example ; for a table as 'TABLE_NAME' with fields N_FIELDNAME,N_CODE,N_ID,VC_NAME,DT_DATE here excluding N_FIELDNAME field all other fields are user input; N_FIELDNAME field value is retrieved from SEQUENCE.If we use
select query on same table 'TABLE_NAME' it will result into Mutating table error .So this piece of trigger code is used to do the above.
CREATE OR REPLACE TRIGGER TRG_NMAE
BEFORE INSERT ON TABLE_NAME
FOR EACH ROW
DECLARE
N_VARIABLE NUMBER(10):=0;
BEGIN
SELECT SEQUENCE_NAME.NEXTVAL INTO N_VARIABLE FROM DUAL;
:NEW.N_FIELDNAME :=N_VARIABLE;
END ;
select query on same table 'TABLE_NAME' it will result into Mutating table error .So this piece of trigger code is used to do the above.
CREATE OR REPLACE TRIGGER TRG_NMAE
BEFORE INSERT ON TABLE_NAME
FOR EACH ROW
DECLARE
N_VARIABLE NUMBER(10):=0;
BEGIN
SELECT SEQUENCE_NAME.NEXTVAL INTO N_VARIABLE FROM DUAL;
:NEW.N_FIELDNAME :=N_VARIABLE;
END ;
DB LINK
A database link is a schema object in one database that enables you to access objects on another database. The other database need not be an Oracle Database system. However, to access non-Oracle systems you must use Oracle Heterogeneous Services. Here example are given from Oracle database to another Oracle database .
CREATE DATABASE LINK "dblink_name"
CONNECT TO user_name
IDENTIFIED BY password
USING sid_name
In Some situation even though user_name,sid_name and password is correct database link created will result to a failure ;this is because Oracle cannot able to get the connection because of some reason ;in-order to meet this situation we want to specify more details for DBLink creation then this script cam be used.
CREATE DATABASE LINK "dblink_name"
CONNECT TO user_name
IDENTIFIED BY 'password'
USING '(DESCRIPTION=
(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=TCP)(HOST=host_name)(PORT=1521)))
(CONNECT_DATA=(SID=sid_name)))';
Errors
1)
By using DBLink DDL operations are not allowed .Such as Create ,Drop ,Truncate etc
Truncate table TABLENAME@DBLINK
ORA-02021: DDL operations are not allowed on a remote database
2)
If a Table which containing LOB datatypes are not able select using dblink
create table test_db ( fild_db clob,num number)
select * from test_db@convert;
ORA-22992: cannot use LOB locators selected from remote tables
Here only selection of datatypes other than LOB are allowed
select num from test_db@convert; --> This Works Fine.
3)
Before dropping a DBLink all transactions should be end else this error will occur.
ORA-02018: database link of same name has an open connection
---------------------------------
CREATE DATABASE LINK "dblink_name"
CONNECT TO user_name
IDENTIFIED BY password
USING sid_name
In Some situation even though user_name,sid_name and password is correct database link created will result to a failure ;this is because Oracle cannot able to get the connection because of some reason ;in-order to meet this situation we want to specify more details for DBLink creation then this script cam be used.
CREATE DATABASE LINK "dblink_name"
CONNECT TO user_name
IDENTIFIED BY 'password'
USING '(DESCRIPTION=
(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=TCP)(HOST=host_name)(PORT=1521)))
(CONNECT_DATA=(SID=sid_name)))';
Errors
1)
By using DBLink DDL operations are not allowed .Such as Create ,Drop ,Truncate etc
Truncate table TABLENAME@DBLINK
ORA-02021: DDL operations are not allowed on a remote database
2)
If a Table which containing LOB datatypes are not able select using dblink
create table test_db ( fild_db clob,num number)
select * from test_db@convert;
ORA-22992: cannot use LOB locators selected from remote tables
Here only selection of datatypes other than LOB are allowed
select num from test_db@convert; --> This Works Fine.
3)
Before dropping a DBLink all transactions should be end else this error will occur.
ORA-02018: database link of same name has an open connection
---------------------------------
May 11, 2009
JOBS /// IsNumeric
Job will execute in a current schema only ;It will not switch between two schemas .
------------------------------
IsNumeric in ORACLE
----------------
select ISNUM from (
select LENGTH(TRIM(TRANSLATE(string1, ' +-.0123456789', ' '))) ISNUM from table_name ) where ISNUM is null
create or replace function isnumeric (param in char) return boolean as
dummy varchar2(100);
begin
dummy:=to_char(to_number(param));
return(true);
exception
when others then
return (false);
end;
/
------------------------------
IsNumeric in ORACLE
----------------
select ISNUM from (
select LENGTH(TRIM(TRANSLATE(string1, ' +-.0123456789', ' '))) ISNUM from table_name ) where ISNUM is null
create or replace function isnumeric (param in char) return boolean as
dummy varchar2(100);
begin
dummy:=to_char(to_number(param));
return(true);
exception
when others then
return (false);
end;
/
Apr 20, 2009
Hidden Table
Create table " " (EMPNO NUMBER(3));
Creates a table with 4 spaces as its name.
When you select the list of tables from all_tables, such tables are not visible.
To access such a table use
Select * From " ";
(Remember you need to give exactly the same number of spaces as you gave while creating the table).
This feature can be used to store information that you feel is confidential for you.
For Example :
You might create tables of this kind
2 spaces + "MYTAB" + 1 space + "FILE" + 3 spaces
When you create such a table only you know how to access it (Unless someone is intelligent than you to guess it).
Creates a table with 4 spaces as its name.
When you select the list of tables from all_tables, such tables are not visible.
To access such a table use
Select * From " ";
(Remember you need to give exactly the same number of spaces as you gave while creating the table).
This feature can be used to store information that you feel is confidential for you.
For Example :
You might create tables of this kind
2 spaces + "MYTAB" + 1 space + "FILE" + 3 spaces
When you create such a table only you know how to access it (Unless someone is intelligent than you to guess it).
Apr 18, 2009
Export Acess to Oracle
This topic deals with the exporting the table and its data from Access to Oracle database . For this first you need is to create a datasource from Start>Programs>Your Oracle Home program>Configuration and Migration Tools path (or from Start>Settings>Control Panel>Administrative Tools you will see a utility named'Data Sources (ODBC)'), you will see a utility named 'Microsoft ODBC Administrator'. Launch that utility to begin the process.
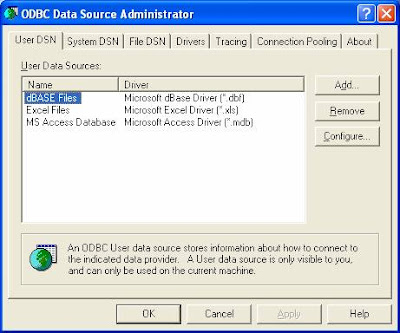
Click on the Add button to add a new data source.

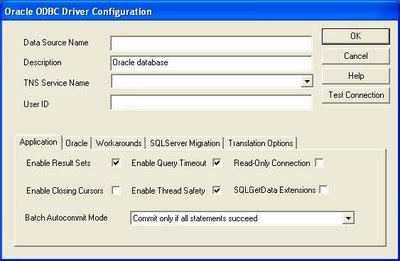
If your connection test was successful, you will see the following:
Then Open the Access file that u want to Export to Oracle .Then at a time only one table in an Access file can be exported to Oracle .After opening Access(.mdb) file select a table say(ie: TEST) and right click the TABLE in OBJECT and select EXPORT




In the status bar of Access file at this time instead of READY status it will show EXPORT

after completing this without error go and check in your oracle database the access table and data will be exported to oracle

Click on the Add button to add a new data source.


If your connection test was successful, you will see the following:

Then Open the Access file that u want to Export to Oracle .Then at a time only one table in an Access file can be exported to Oracle .After opening Access(.mdb) file select a table say(ie: TEST) and right click the TABLE in OBJECT and select EXPORT




In the status bar of Access file at this time instead of READY status it will show EXPORT

after completing this without error go and check in your oracle database the access table and data will be exported to oracle
Apr 9, 2009
Table Creation/// NOT NULL (check constraint)
Everything (Table Creation including Primary ,Foreign key ,Check constraint and giving user defined CONSTRAINT NAME for NOT NULL CONSTRAINT) in a single Script ;without using alter command for predefined constraints till design time
CREATE TABLE STUDENTS_MAST(
N_STUDID NUMBER(5),CONSTRAINT PK_STUDID PRIMARY KEY(N_STUDID))
CREATE TABLE STUDENT_TEAM (
N_STDTMID NUMBER(10) ,CONSTRAINT PK_STUDENT_TEAM PRIMARY KEY(N_STUDTMID),
N_STUDID NUMBER(10),CONSTRAINT FK_STUD_TEAM_EMPID FOREIGN KEY(N_STUDID) REFERENCES STUDENTS_MAST(N_STUDID),
C_TLFLAG CHAR(1) ,CONSTRAINT CK_STUD_TEAM_TLFLAG CHECK (C_TLFLAG IN ('Y','N')) ,
D_STDATE DATE CONSTRAINT NN_STUD_TEAM_STDATE NOT NULL,
D_ENDDATE DATE CONSTRAINT NN_STUD_TEAM_ENDATE NOT NULL,
D_ENTRYDAT DATE DEFAULT SYSDATE )
--------------
CREATE TABLE STUDENT_TEAM (N_STDTMID NUMBER(10) CONSTRAINT NN_STUDENT_STATUS_TMID NOT NULL)
ALTER TABLE STUDENT_STATUS ADD ( CONSTRAINT NN_ST_STATUS_TMID CHECK (N_STDTMID IS NOT NULL))
Both Scripts will restrict not null values but error code will be different first script results
ORA-01407: cannot update to NULL
ORA-01400: cannot insert NULL into N_STDTMID
second script results
Another difference is the null(nullable) field will be true when null is checked by first script but it will not be for second second script
-----------
During check constraint creation if already exists some records in the particular table which violates the new check constraint.This error will be displayed
ORA-02293: cannot validate (##########) - check constraint violated
-----------------
CREATE TABLE STUDENTS_MAST(
N_STUDID NUMBER(5),CONSTRAINT PK_STUDID PRIMARY KEY(N_STUDID))
CREATE TABLE STUDENT_TEAM (
N_STDTMID NUMBER(10) ,CONSTRAINT PK_STUDENT_TEAM PRIMARY KEY(N_STUDTMID),
N_STUDID NUMBER(10),CONSTRAINT FK_STUD_TEAM_EMPID FOREIGN KEY(N_STUDID) REFERENCES STUDENTS_MAST(N_STUDID),
C_TLFLAG CHAR(1) ,CONSTRAINT CK_STUD_TEAM_TLFLAG CHECK (C_TLFLAG IN ('Y','N')) ,
D_STDATE DATE CONSTRAINT NN_STUD_TEAM_STDATE NOT NULL,
D_ENDDATE DATE CONSTRAINT NN_STUD_TEAM_ENDATE NOT NULL,
D_ENTRYDAT DATE DEFAULT SYSDATE )
--------------
CREATE TABLE STUDENT_TEAM (N_STDTMID NUMBER(10) CONSTRAINT NN_STUDENT_STATUS_TMID NOT NULL)
ALTER TABLE STUDENT_STATUS ADD ( CONSTRAINT NN_ST_STATUS_TMID CHECK (N_STDTMID IS NOT NULL))
Both Scripts will restrict not null values but error code will be different first script results
ORA-01407: cannot update to NULL
ORA-01400: cannot insert NULL into N_STDTMID
second script results
Another difference is the null(nullable) field will be true when null is checked by first script but it will not be for second second script
-----------
During check constraint creation if already exists some records in the particular table which violates the new check constraint.This error will be displayed
ORA-02293: cannot validate (##########) - check constraint violated
-----------------
Apr 7, 2009
Oracle Wokspace 4
dbms_wm.gotodate
begin
dbms_wm.gotoworkspace('B_focus_1');
end;
insert into test values (6,'Wayanad','YS','n',null,sysdate);
select * from test order by one ;
begin
dbms_wm.gotodate( (sysdate-5)) ;
end;
select * from test order by one ;
begin
dbms_wm.gotoworkspace('B_focus_1');
end;
select * from test order by one ;
Freezeworkspace
begin
dbms_wm.freezeworkspace('B_focus_1', 'READ_ONLY');
end;
insert into test values (6,'Wayanad','YS','n',null,sysdate);
This Error will be throwed when we try any DML operations (here to insert data) into a readonly workspace.
ORA-20123: workspace 'B_focus_1' is currently frozen in READ_ONLY mode
Export And Import Implications
The following implications are a result of version-enabling tables:
* Imports of version-enabled tables can only be performed if the target database has Workspace Manager installed and no workspaces defined other than LIVE.
* Only full database exports are supported with version-enabled databases.
* The IGNORE=Y parameter must be set for imports of version enabled databases.
* Imports of version-enabled databases cannot use the FROMUSER and TOUSER functioanlity.
For More about workspaces Refer here
begin
dbms_wm.gotoworkspace('B_focus_1');
end;
insert into test values (6,'Wayanad','YS','n',null,sysdate);
select * from test order by one ;
begin
dbms_wm.gotodate( (sysdate-5)) ;
end;
select * from test order by one ;
begin
dbms_wm.gotoworkspace('B_focus_1');
end;
select * from test order by one ;
Freezeworkspace
begin
dbms_wm.freezeworkspace('B_focus_1', 'READ_ONLY');
end;
insert into test values (6,'Wayanad','YS','n',null,sysdate);
This Error will be throwed when we try any DML operations (here to insert data) into a readonly workspace.
ORA-20123: workspace 'B_focus_1' is currently frozen in READ_ONLY mode
Export And Import Implications
The following implications are a result of version-enabling tables:
* Imports of version-enabled tables can only be performed if the target database has Workspace Manager installed and no workspaces defined other than LIVE.
* Only full database exports are supported with version-enabled databases.
* The IGNORE=Y parameter must be set for imports of version enabled databases.
* Imports of version-enabled databases cannot use the FROMUSER and TOUSER functioanlity.
For More about workspaces Refer here
Mar 26, 2009
Oracle Wokspace 3
To Refresh workspace
begin
dbms_wm.gotoworkspace('B_focus_9');
dbms_wm.refreshworkspace('B_focus_9');
end;
But if there are conflicts refreshworkspace will result an error
ORA-20056: conflicts detected for workspace: 'B_focus_9' in table: 'USER.TEST'
LIVE WORKSPACE CANNOT BE REFRESHED
The two rows that changed in both the LIVE and the 'B_focus_9' workspace create a conflict. These conflicts can be seen from the view Test_conf. But first go to the 'B_focus_9' workspace. The conflicts are not visible in this view while being in the LIVE workspace.
--------------------------
To Resolve this conflicts
SELECT * FROM test_conf ORDER BY wm_workspace;
begin
dbms_wm.gotoworkspace('B_focus_9');
dbms_wm.beginresolve('B_focus_9');
dbms_wm.resolveconflicts('B_focus_9','TEST',null/*where clause*/,'PARENT');
commit;
end;
begin
dbms_wm.commitresolve('B_focus_9');
end;
SELECT * FROM test_conf ORDER BY wm_workspace;
After resolving this conflict the workspace can be refreshed
begin
dbms_wm.refreshworkspace('B_focus_9');
end;
Merge Workspace
begin
dbms_wm.mergeworkspace('B_focus_9');
end;
When B_focus_9 workspace is merged into the LIVE workspace. A merge is the opposite of a refresh : it updates the parent workspace (LIVE) with the changes made to the merged workspace (B_focus_9). Where as refresh operation updates the refreshing workspace.
---------------------------------
After MergeWorkspace See Difference
begin
dbms_wm.gotoworkspace('B_focus_1');
end;
select * from test order by one

begin
dbms_wm.gotoworkspace('B_focus_9');
end;
select * from test order by one

begin
dbms_wm.gotoworkspace('LIVE');
end;
select * from test order by one
Here parent workspace (LIVE) was updated by merged workspace (B_focus_9) .
----------------
begin
dbms_wm.gotoworkspace('B_focus_9');
dbms_wm.refreshworkspace('B_focus_9');
end;
But if there are conflicts refreshworkspace will result an error
ORA-20056: conflicts detected for workspace: 'B_focus_9' in table: 'USER.TEST'
LIVE WORKSPACE CANNOT BE REFRESHED
The two rows that changed in both the LIVE and the 'B_focus_9' workspace create a conflict. These conflicts can be seen from the view Test_conf. But first go to the 'B_focus_9' workspace. The conflicts are not visible in this view while being in the LIVE workspace.
--------------------------
To Resolve this conflicts
SELECT * FROM test_conf ORDER BY wm_workspace;
begin
dbms_wm.gotoworkspace('B_focus_9');
dbms_wm.beginresolve('B_focus_9');
dbms_wm.resolveconflicts('B_focus_9','TEST',null/*where clause*/,'PARENT');
commit;
end;
begin
dbms_wm.commitresolve('B_focus_9');
end;
SELECT * FROM test_conf ORDER BY wm_workspace;
After resolving this conflict the workspace can be refreshed
begin
dbms_wm.refreshworkspace('B_focus_9');
end;
Merge Workspace
begin
dbms_wm.mergeworkspace('B_focus_9');
end;
When B_focus_9 workspace is merged into the LIVE workspace. A merge is the opposite of a refresh : it updates the parent workspace (LIVE) with the changes made to the merged workspace (B_focus_9). Where as refresh operation updates the refreshing workspace.
---------------------------------
After MergeWorkspace See Difference
begin
dbms_wm.gotoworkspace('B_focus_1');
end;
select * from test order by one

begin
dbms_wm.gotoworkspace('B_focus_9');
end;
select * from test order by one

begin
dbms_wm.gotoworkspace('LIVE');
end;
select * from test order by one
Here parent workspace (LIVE) was updated by merged workspace (B_focus_9) .
----------------
Oracle Workspace 2
The merge operation does not currently work with versioned tables. The optimizer translates the merge into
insert/update statements on the underlying _LT table
To have several versions of data
create table TEST (
one number primary key, -- Without primary key: ORA-20133:
two varchar2(15), three char(2), four clob,
five blob, six date );
insert into test values (1,'Cochin','NO','Kochi is a vibrant city situated on the south-west coast of the Indian peninsula in the breathtakingly scenic and prosperous state of Kerala, hailed as Gods Own Country',null,sysdate);
insert into test values (2,'Kerala','YS','n',null,sysdate);
insert into test values (3,'TVM','NO','n',null,sysdate);
insert into test values (4,'Calicut','NO','n',null,sysdate);
insert into test values (5,'Kannur','YS','n',null,sysdate);
commit;
begin
dbms_wm.enableversioning ('test');
end;
begin
dbms_wm.createworkspace ('B_focus_1');
dbms_wm.createworkspace ('B_focus_9' );
end;
begin
dbms_wm.gotoworkspace('B_focus_1');
dbms_wm.createworkspace ('test' );
end;
select workspace, parent_workspace from user_workspaces;
select * from test order by one;
update test set two='Kasargode',three='NO',four='Top end of Kerala',Six=sysdate where one=2;
commit;
begin
dbms_wm.gotoworkspace('LIVE');
end;
select * from test order by one

begin
dbms_wm.gotoworkspace('B_focus_9');
end;
select * from test order by one
update test set two='Thrissur',three='NO',four='Middle of Kerala',Six=sysdate where one=2;
commit;
select * from test order by one
begin
dbms_wm.gotoworkspace('test');
end;
select * from test order by one
insert/update statements on the underlying _LT table
To have several versions of data
create table TEST (
one number primary key, -- Without primary key: ORA-20133:
two varchar2(15), three char(2), four clob,
five blob, six date );
insert into test values (1,'Cochin','NO','Kochi is a vibrant city situated on the south-west coast of the Indian peninsula in the breathtakingly scenic and prosperous state of Kerala, hailed as Gods Own Country',null,sysdate);
insert into test values (2,'Kerala','YS','n',null,sysdate);
insert into test values (3,'TVM','NO','n',null,sysdate);
insert into test values (4,'Calicut','NO','n',null,sysdate);
insert into test values (5,'Kannur','YS','n',null,sysdate);
commit;
begin
dbms_wm.enableversioning ('test');
end;
begin
dbms_wm.createworkspace ('B_focus_1');
dbms_wm.createworkspace ('B_focus_9' );
end;
begin
dbms_wm.gotoworkspace('B_focus_1');
dbms_wm.createworkspace ('test' );
end;
select workspace, parent_workspace from user_workspaces;
select * from test order by one;
update test set two='Kasargode',three='NO',four='Top end of Kerala',Six=sysdate where one=2;
commit;
begin
dbms_wm.gotoworkspace('LIVE');
end;
select * from test order by one

begin
dbms_wm.gotoworkspace('B_focus_9');
end;
select * from test order by one
update test set two='Thrissur',three='NO',four='Middle of Kerala',Six=sysdate where one=2;
commit;
select * from test order by one
begin
dbms_wm.gotoworkspace('test');
end;
select * from test order by one
Mar 25, 2009
Oracle Workspace 1
Workspace Manager PL/SQL APIs
The PL/SQL APIs in the DBMS_WM package can be executed
* Workspace operations: create,refresh,merge,rollback remove,goto,compress,alter
* Savepoints: create, alter, goto
* History: goto date
* Privileges: access, create, delete, rollback and merge workspace
* Access Modes: read, write, management or no access to workspaces
* Locks: exclusive and shared workspace locks to prevent data update conflicts
* Find Differences: compare savepoints and workspaces
* Detect / Resolve Conflicts: Automatically detect and resolve conflicts
When a particular table is versioned primary key index is rebuild version field is added with the current primary key fields inorder to uniquely identify each row version .Each table that is versioned with the workspace manager must have a primary key.No issue if there is a Foreign Key
To get Lock Mode
SELECT dbms_wm.GetLockMode FROM dual;
Some Errors
-----------
(I)ORA-20101: child table must be version enabled (This error occur if TEST table is referenced by another table TESTCHILD ;if TESTCHILD is version enabled then only TEST table can be versioned )
(II)ORA-20100: 'USER.TEST' is both parent and child tables of referential integrity constraints
If a field of TEST table is referenced by another field of TEST table itself such tables cannot be version-
enabled ie:( In Scott.EMP table MGR field is referenced by EMPNO field )
ALTER TABLE EMP ADD CONSTRAINT FK_EMP
FOREIGN KEY (MGR) REFERENCES EMP (EMPNO) )
(III) Temporary Table cannot be version enabled
ORA-20229:statement 'CREATE INDEX TMP_TEST_PKI$ on TMP_TEST_LT(A)LOGGING PCTFREE 10 INITRANS 2 M' failed during EnableVersioning.Error:
ORA-14451: unsupported feature with temporary table
Referential integrity constraints cannot be added after versioning is enabled. They must be present before version-enabling
------------------*------------------*---------------------*----------------
EXEC DBMS_WM.FINDRICSET('B_focus_1', 'RICTEST') ; --CREATE A TABLE WITH FIELD TABLE_OWNER & TABLE_NAME WITH DATA
SELECT dbms_wm.GetPrivs('LIVE') FROM dual ; //GET Privileges of particular workspace
To Get Lock Mode
SELECT dbms_wm.GetLockMode FROM dual ;
DECLARE
lockmode varchar2(1);
begin
lockMode := sys.lt_ctx_pkg.lock_Mode;
dbms_output.put_line(lockMode);
end;
The min & max time that Oracle supports
SELECT DBMS_WM.max_time,DBMS_WM.min_time FROM DUAL; (from 10g onwards)
The PL/SQL APIs in the DBMS_WM package can be executed
* Workspace operations: create,refresh,merge,rollback remove,goto,compress,alter
* Savepoints: create, alter, goto
* History: goto date
* Privileges: access, create, delete, rollback and merge workspace
* Access Modes: read, write, management or no access to workspaces
* Locks: exclusive and shared workspace locks to prevent data update conflicts
* Find Differences: compare savepoints and workspaces
* Detect / Resolve Conflicts: Automatically detect and resolve conflicts
When a particular table is versioned primary key index is rebuild version field is added with the current primary key fields inorder to uniquely identify each row version .Each table that is versioned with the workspace manager must have a primary key.No issue if there is a Foreign Key
To get Lock Mode
SELECT dbms_wm.GetLockMode FROM dual;
Some Errors
-----------
(I)ORA-20101: child table must be version enabled (This error occur if TEST table is referenced by another table TESTCHILD ;if TESTCHILD is version enabled then only TEST table can be versioned )
(II)ORA-20100: 'USER.TEST' is both parent and child tables of referential integrity constraints
If a field of TEST table is referenced by another field of TEST table itself such tables cannot be version-
enabled ie:( In Scott.EMP table MGR field is referenced by EMPNO field )
ALTER TABLE EMP ADD CONSTRAINT FK_EMP
FOREIGN KEY (MGR) REFERENCES EMP (EMPNO) )
(III) Temporary Table cannot be version enabled
ORA-20229:statement 'CREATE INDEX TMP_TEST_PKI$ on TMP_TEST_LT(A)LOGGING PCTFREE 10 INITRANS 2 M' failed during EnableVersioning.Error:
ORA-14451: unsupported feature with temporary table
Referential integrity constraints cannot be added after versioning is enabled. They must be present before version-enabling
------------------*------------------*---------------------*----------------
EXEC DBMS_WM.FINDRICSET('B_focus_1', 'RICTEST') ; --CREATE A TABLE WITH FIELD TABLE_OWNER & TABLE_NAME WITH DATA
SELECT dbms_wm.GetPrivs('LIVE') FROM dual ; //GET Privileges of particular workspace
To Get Lock Mode
SELECT dbms_wm.GetLockMode FROM dual ;
DECLARE
lockmode varchar2(1);
begin
lockMode := sys.lt_ctx_pkg.lock_Mode;
dbms_output.put_line(lockMode);
end;
The min & max time that Oracle supports
SELECT DBMS_WM.max_time,DBMS_WM.min_time FROM DUAL; (from 10g onwards)
Mar 19, 2009
Oracle Workspace
With Oracle's Workspace Manager it's possible to have several versions of data. That is, data can be changed, thus making a new version, without affecting application data.For this a new workspace is to be created and the table is to be versioned
Workspace allows multiple transactions to exist within one table in a schema. This allows several departments or functional areas to work against a single schema without interfering with data from other groups. Changes to version-enabled tables are captured as new rows within the workspace. These changes are invisible to other workspaces until they are merged into a parent workspace.
The functionality (Packages, Procedures, Functions) used for the Workspace Manager are found in the wmsys schema.
In a workspace hierarchy consisting of Live->PreProduction->Development workspaces, the Development workspace can see all row changes made in the PreProduction workspace, along with all committed data from non-version-enabled tables belonging to the Live workspace. In addition it can see data from version-enabled tables in Live as they were when the PreProduction workspace was created. Once a workspace is refreshed, all changes can be cascaded down the hierarchy.
Workspace Manager makes only a copy of row it is changed ,which reduce hardware , software and time needed to manage multiple version of data in different schemas .A workspace is a virtual environment not physical storage.The default workspace is called LIVE.
Main concepts used for workspace are Instead of Triggers and Context .
For More On WorkSpace
To get Version
SELECT dbms_wm.getversion FROM dual;
To create Workspace
begin
dbms_wm.createworkspace('B_focus_1');
end;
select workspace, parent_workspace from user_workspaces;
To move to workspace
begin
dbms_wm.gotoworkspace('B_focus_1');
end;
To enable versoning for a table
begin
dbms_wm.enableversioning (table_name,hist);
end;
1)The length of a table name must not exceed 25 characters. The name is not case sensitive
2) Hist
NONE: No modifications to the table are tracked. (This is the default.)
VIEW_W_OVERWRITE: The with overwrite (W_OVERWRITE) option: A view named_HIST is created to contain history information, but it will show only the most recent modifications to the same version of the table. A history of modifications to the version is not maintained; that is, subsequent changes to a row in the same version overwrite earlier changes. (The CREATETIME column of the _HIST view contains only the time of the most recent update.)
VIEW_WO_OVERWRITE: The without overwrite (WO_OVERWRITE) option: A view named_HIST is created to contain history information, and it will show all modifications to the same version of the table. A history of modifications to the version is maintained; that is, subsequent changes to a row in the same version do not overwrite earlier changes.
If the table is version-enabled with the VIEW_WO_OVERWRITE hist option specified, this option can later be disabled and re-enabled by calling the SetWoOverwriteOFF Procedure and SetWoOverwriteON Procedure.
begin
DBMS_WM.SetWoOverwriteOFF();
end;
This procedure enables the VIEW_WO_OVERWRITE history option that had been disabled by the SetWoOverwriteOFF Procedure.
begin
DBMS_WM.SetWoOverwriteON();
end;
---------------------------------------
a)Only the owner of a table can enable versioning on the table.
b)Tables that are version-enabled and users that own version-enabled tables cannot be deleted. You must first disable versioning on the relevant table or tables.
c)Tables owned by SYS cannot be version-enabled.
d)DDL operations are not allowed on version-enabled tables.
e)Index-organized tables cannot be version-enabled.
f)Object tables cannot be version-enabled.
g)A table with one or more columns of LONG data type cannot be version-enabled.
------------------------------------------------------------
Example
begin
dbms_wm.enableversioning ('TEST');
end;
This will rename the TEST table to TEST_LT(LT stands for Long Transaction ie:Completes over days or week ) and create a view called TEST (which contains original data for more detail refer script of view) addition to this 9 other views will be created.The view uses instead-of triggers to perform all operations against the version enabled table. This hides a lot of the versioning mechanism from the users.
The TEST_LT table has the following additional columns:
VERSION NOT NULL NUMBER(38)
NEXTVER VARCHAR2(500)
DELSTATUS NUMBER(38)
LTLOCK VARCHAR2(100)
Values for following tables when table is version enabled (0,-1,10,!O!)
Test_MV (Materialized view) View it contains data ;which the field is not affected ;with two extra fields WM_MODIFIEDBY and WM_OPTYPE
Test_base view contains the field of original table in addition RID,version,nextver,delstatus,ltlock
Test_BPKC contains fields Rowids of child,parent and base ,childstate ,parentstate ,DS and VER of child,parent & base (ie : 12 fields) if we are in LIVE workspace there will not be an data in it because it is in parent state if it is in any of child workspace there will be data
Test_PKC contains all the fields of Text_BPKC excluding Firstchildver
TEST_HIST This view is created only if ; during table versioning (ie: enableversioning) if we supply hist parameter if hist parameter is NONE then this view will not be there to track history details .
IF active workspace is LIVE then TEST,TEST_BASE,TEST_MV view only have records
Test_conf (Conflict) view contains all fields in Test addition to those wm_workspace,wm_delted
To disable versoning
begin
dbms_wm.disableversioning ('TEST');
end;
To compress WorkSpace
begin
dbms_wm.compressworkspace('LIVE');
end;
To view curent workspace
SELECT DBMS_WM.getworkspace FROM DUAL;
SELECT DBMS_WM.isworkspaceoccupied('B_focus_1') FROM DUAL;
To view versionenabled tables
select * from wmsys.wm$table_parvers_view
SELECT * FROM user_wm_versioned_tables;
To get current version number
select * from wmsys.WM$CURRENT_VER_VIEW;
To get current and next version
select * from wmsys.WM$CURRENT_NEXTVERS_VIEW;
To get current hierarchy of
select * from wmsys.WM$CURRENT_HIERARCHY_VIEW;
select * from wmsys.WM$CONF1_HIERARCHY_VIEW;
To get parent of a workspace
You should be in a workspace other than LIVE then only we get data from this view ; because for LIVE workspace is parent of .
select * from wmsys.WM$PARENT_HIERARCHY_VIEW;
To get constraints of version enabled tables
select * from wmsys.USER_WM_CONSTRAINTS;
select * from wmsys.USER_WM_IND_COLUMNS;
To get details of versionenabled tables that are modified
select * from wmsys.USER_WM_MODIFIED_TABLES;
To get trigger details on version enabled tables
USER_WM_TAB_TRIGGERS;
To get details of locked tables
select * from wmsys.USER_WM_LOCKED_TABLES;
To get
select * from wmsys.USER_WM_VERSIONED_TABLES;
To get errors in workspace
select * from wmsys.USER_WM_VT_ERRORS;
To get savepointdetails
USER_WORKSPACE_SAVEPOINTS;
To get foreign key of version enabled tables
USER_WM_RIC_INFO;
To get current hierarchy and depth of
select * from wmsys.ALL_VERSION_HVIEW_WDEPTH;
--------------------------------------------------------
Workspace allows multiple transactions to exist within one table in a schema. This allows several departments or functional areas to work against a single schema without interfering with data from other groups. Changes to version-enabled tables are captured as new rows within the workspace. These changes are invisible to other workspaces until they are merged into a parent workspace.
The functionality (Packages, Procedures, Functions) used for the Workspace Manager are found in the wmsys schema.
In a workspace hierarchy consisting of Live->PreProduction->Development workspaces, the Development workspace can see all row changes made in the PreProduction workspace, along with all committed data from non-version-enabled tables belonging to the Live workspace. In addition it can see data from version-enabled tables in Live as they were when the PreProduction workspace was created. Once a workspace is refreshed, all changes can be cascaded down the hierarchy.
Workspace Manager makes only a copy of row it is changed ,which reduce hardware , software and time needed to manage multiple version of data in different schemas .A workspace is a virtual environment not physical storage.The default workspace is called LIVE.
Main concepts used for workspace are Instead of Triggers and Context .
For More On WorkSpace
To get Version
SELECT dbms_wm.getversion FROM dual;
To create Workspace
begin
dbms_wm.createworkspace('B_focus_1');
end;
select workspace, parent_workspace from user_workspaces;
To move to workspace
begin
dbms_wm.gotoworkspace('B_focus_1');
end;
To enable versoning for a table
begin
dbms_wm.enableversioning (table_name,hist);
end;
1)The length of a table name must not exceed 25 characters. The name is not case sensitive
2) Hist
NONE: No modifications to the table are tracked. (This is the default.)
VIEW_W_OVERWRITE: The with overwrite (W_OVERWRITE) option: A view named
VIEW_WO_OVERWRITE: The without overwrite (WO_OVERWRITE) option: A view named
If the table is version-enabled with the VIEW_WO_OVERWRITE hist option specified, this option can later be disabled and re-enabled by calling the SetWoOverwriteOFF Procedure and SetWoOverwriteON Procedure.
begin
DBMS_WM.SetWoOverwriteOFF();
end;
This procedure enables the VIEW_WO_OVERWRITE history option that had been disabled by the SetWoOverwriteOFF Procedure.
begin
DBMS_WM.SetWoOverwriteON();
end;
---------------------------------------
a)Only the owner of a table can enable versioning on the table.
b)Tables that are version-enabled and users that own version-enabled tables cannot be deleted. You must first disable versioning on the relevant table or tables.
c)Tables owned by SYS cannot be version-enabled.
d)DDL operations are not allowed on version-enabled tables.
e)Index-organized tables cannot be version-enabled.
f)Object tables cannot be version-enabled.
g)A table with one or more columns of LONG data type cannot be version-enabled.
------------------------------------------------------------
Example
begin
dbms_wm.enableversioning ('TEST');
end;
This will rename the TEST table to TEST_LT(LT stands for Long Transaction ie:Completes over days or week ) and create a view called TEST (which contains original data for more detail refer script of view) addition to this 9 other views will be created.The view uses instead-of triggers to perform all operations against the version enabled table. This hides a lot of the versioning mechanism from the users.
The TEST_LT table has the following additional columns:
VERSION NOT NULL NUMBER(38)
NEXTVER VARCHAR2(500)
DELSTATUS NUMBER(38)
LTLOCK VARCHAR2(100)
Values for following tables when table is version enabled (0,-1,10,!O!)
Test_MV (Materialized view) View it contains data ;which the field is not affected ;with two extra fields WM_MODIFIEDBY and WM_OPTYPE
Test_base view contains the field of original table in addition RID,version,nextver,delstatus,ltlock
Test_BPKC contains fields Rowids of child,parent and base ,childstate ,parentstate ,DS and VER of child,parent & base (ie : 12 fields) if we are in LIVE workspace there will not be an data in it because it is in parent state if it is in any of child workspace there will be data
Test_PKC contains all the fields of Text_BPKC excluding Firstchildver
TEST_HIST This view is created only if ; during table versioning (ie: enableversioning) if we supply hist parameter if hist parameter is NONE then this view will not be there to track history details .
IF active workspace is LIVE then TEST,TEST_BASE,TEST_MV view only have records
Test_conf (Conflict) view contains all fields in Test addition to those wm_workspace,wm_delted
To disable versoning
begin
dbms_wm.disableversioning ('TEST');
end;
To compress WorkSpace
begin
dbms_wm.compressworkspace('LIVE');
end;
To view curent workspace
SELECT DBMS_WM.getworkspace FROM DUAL;
To view versionenabled tables
select * from wmsys.wm$table_parvers_view
SELECT * FROM user_wm_versioned_tables;
select * from wmsys.
select * from wmsys.
select * from wmsys.
select * from wmsys.
You should be in a workspace other than LIVE then only we get data from this view ; because for LIVE workspace is parent of .
select * from wmsys.
select * from wmsys.
select * from wmsys.
select * from wmsys.
To get savepoint
--------------------------------------------------------
Mar 13, 2009
Insertion with condition
If there is a table with fields rt (number) which is a primary key and DF varchar2.If there r 10 records and first 5 records r deleted then when inserting records it want to start from 1 and then increment after each insert .
create table DF(DF VARCHAR2(3000),RT NUMBER(2) not null);
alter table DF add constraint E primary key (RT);
insert into df(rt,df)
with
all_numbers as (select level num from dual connect by level <=99),
available_number as (select num,rownum line from
(select num from all_numbers minus select rt from df order by 1) order by num )
select num,'B-'||rownum from available_number where rownum <=10;
----------------------------------------------------------------------
create table DF(DF VARCHAR2(3000),RT NUMBER(2) not null);
alter table DF add constraint E primary key (RT);
insert into df(rt,df)
with
all_numbers as (select level num from dual connect by level <=99),
available_number as (select num,rownum line from
(select num from all_numbers minus select rt from df order by 1) order by num )
select num,'B-'||rownum from available_number where rownum <=10;
----------------------------------------------------------------------
Mar 9, 2009
Unknown Functions
A Word : Risk of using Oracle Undocumented functions or procedures here is that without any notice Oracle may remove them and there will not be support from ORACLE
To get similar characters among the two fields (from 9i onwards)
SELECT merge$actions('lNvl', 'pppl') FROM dual;
SELECT replace(merge$actions(1204, 1260),'BB','') FROM dual;
------------------------------------------------------------------------------
To view blob details (from 10g onwards)
SELECT sys_op_cl2c(ad_finaltext),s.product_id FROM pm.print_media s
-----------------------------------------------------------------------------
To get blocknumber of a particular tables (from 9i onwards)
select dbms_rowid.rowid_block_number(rowid) from dual;
SELECT COUNT(DISTINCT dbms_rowid.rowid_block_number(rowid)),
COUNT( dbms_rowid.rowid_block_number(rowid))FROM pm.print_media;
----------------------------------------------------------------------
To convert into HEX (from 9i onwards)
SELECT sys_op_descend('9')FROM dual;
-----------------------------------------------------------------------------
To show generate null coloumn (from 9i onwards)
SELECT sys_op_lvl(1,21,1,1,1,1 ,2) FROM dual;
-------------------------------------------------------------------------------
To generates and returns a globally unique identifier of 16 bytes The returned data type is RAW(16) (from 9i onwards)
SELECT sys_guid() FROM dual;
-----------------------------------------------------------------------
To get comma seperated values in rows wise (from 10g onwards)
select sys.odcivarchar2list('Football','Rugby') from dual;
select column_value from table(
select sys.odcivarchar2list('Football','Rugby') from dual);
-----------------------------------------------------------------------
To get data in ascii characters (from 10g onwards)
SELECT sys_op_c2c(9068986) FROM dual;
-------------------------------------------------------------------------
TO get number representation of rowid (from 9i onwards)
SELECT rowid, sys_op_rpb(rowid),dbms_rowid.rowid_block_number(rowid) FROM scott.emp
-------------------------------------------------------------------------
Similar to null (from 10g onwards)
SELECT sys_fbt_insdel, decode(sys_fbt_insdel,null,1,0) FROM dual;
-------------------------------------------------------------------------
To convert hex to num (from 9i onwards)
SELECT sys_op_rawtonum('000000FF'),UTL_RAW.CAST_FROM_BINARY_INTEGER(255) FROM dual;
-------------------------------------------------------------------------
To check whether a number is even or odd (from 9i onwards)
Return the value of the bit at position N
The return value is 0 or 1
SELECT sys_op_vecbit('255',0),sys_op_vecbit('255',1),sys_op_vecbit('22',1),sys_op_vecbit('22',0) FROM dual;
-------------------------------------------------------------------------
Return the binary AND of two hex values (from 9i onwards)
SELECT sys_op_vecand('FC','FD') from dual;
SELECT sys_op_vecand('FF','FD') from dual;
-----------------------------------------------------------------------
Return the binary OR of two hex values (from 9i onwards)
SELECT sys_op_vecor(('FC'),('FE')) from dual;
-----------------------------------------------------------------------
Return the binary XOR of two hex values (from 9i onwards)
SELECT sys_op_vecxor(('FF'),('FE')) from dual;
-----------------------------------------------------------------------
To get ref value visible (from 9i onwards)
SELECT sys_op_r2o(CUSTOMER_REF),CUSTOMER_REF FROM oe.oc_orders WHERE rownum = 1;
--------------------------------------------------------------------------------
Query to show which all values are present in a table and not present
SELECT nvl(to_char(e.EID), column_value||' Not found') empno from table(sys.odcinumberlist(7369,7370,7566,7555,1))l left outer join emp e on e.EID = l.column_value order by 1
sys.odcinumberlist is the default varray that oracle supplies . If you want to create your own type
CREATE TYPE typ_p is varray (32767) of number
SELECT * from table(typ_p(7369,7370,7566,7555,1 ))
-----------------------------------------------------------------------
To compare null (from 9i onwards)
SELECT 'hi there' FROM DUAL WHERE NULL = NULL;
SELECT 'hi there' FROM DUAL WHERE sys_op_map_nonnull (NULL) = sys_op_map_nonnull (NULL);
SELECT 'hi there' FROM DUAL WHERE nvl(null,'FF')='FF';
select sys_op_map_nonnull(null) from dual; --similat to nvl(null,'FF')
select * from dual where sys_op_map_nonnull(null) = 'FF';
SELECT 'hi there' FROM DUAL WHERE to_char(1||NULL) = to_char(1||NULL);
-----------------------------------------------------------------------
To get similar characters among the two fields (from 9i onwards)
SELECT merge$actions('lNvl', 'pppl') FROM dual;
SELECT replace(merge$actions(1204, 1260),'BB','') FROM dual;
------------------------------------------------------------------------------
To view blob details (from 10g onwards)
SELECT sys_op_cl2c(ad_finaltext),s.product_id FROM pm.print_media s
-----------------------------------------------------------------------------
To get blocknumber of a particular tables (from 9i onwards)
select dbms_rowid.rowid_block_number(rowid) from dual;
SELECT COUNT(DISTINCT dbms_rowid.rowid_block_number(rowid)),
COUNT( dbms_rowid.rowid_block_number(rowid))FROM pm.print_media;
----------------------------------------------------------------------
To convert into HEX (from 9i onwards)
SELECT sys_op_descend('9')FROM dual;
-----------------------------------------------------------------------------
To show generate null coloumn (from 9i onwards)
SELECT sys_op_lvl(1,21,1,1,1,1 ,2) FROM dual;
-------------------------------------------------------------------------------
To generates and returns a globally unique identifier of 16 bytes The returned data type is RAW(16) (from 9i onwards)
SELECT sys_guid() FROM dual;
-----------------------------------------------------------------------
To get comma seperated values in rows wise (from 10g onwards)
select sys.odcivarchar2list('Football','Rugby') from dual;
select column_value from table(
select sys.odcivarchar2list('Football','Rugby') from dual);
-----------------------------------------------------------------------
To get data in ascii characters (from 10g onwards)
SELECT sys_op_c2c(9068986) FROM dual;
-------------------------------------------------------------------------
TO get number representation of rowid (from 9i onwards)
SELECT rowid, sys_op_rpb(rowid),dbms_rowid.rowid_block_number(rowid) FROM scott.emp
-------------------------------------------------------------------------
Similar to null (from 10g onwards)
SELECT sys_fbt_insdel, decode(sys_fbt_insdel,null,1,0) FROM dual;
-------------------------------------------------------------------------
To convert hex to num (from 9i onwards)
SELECT sys_op_rawtonum('000000FF'),UTL_RAW.CAST_FROM_BINARY_INTEGER(255) FROM dual;
-------------------------------------------------------------------------
To check whether a number is even or odd (from 9i onwards)
Return the value of the bit at position N
The return value is 0 or 1
SELECT sys_op_vecbit('255',0),sys_op_vecbit('255',1),sys_op_vecbit('22',1),sys_op_vecbit('22',0) FROM dual;
-------------------------------------------------------------------------
Return the binary AND of two hex values (from 9i onwards)
SELECT sys_op_vecand('FC','FD') from dual;
SELECT sys_op_vecand('FF','FD') from dual;
-----------------------------------------------------------------------
Return the binary OR of two hex values (from 9i onwards)
SELECT sys_op_vecor(('FC'),('FE')) from dual;
-----------------------------------------------------------------------
Return the binary XOR of two hex values (from 9i onwards)
SELECT sys_op_vecxor(('FF'),('FE')) from dual;
-----------------------------------------------------------------------
To get ref value visible (from 9i onwards)
SELECT sys_op_r2o(CUSTOMER_REF),CUSTOMER_REF FROM oe.oc_orders WHERE rownum = 1;
--------------------------------------------------------------------------------
Query to show which all values are present in a table and not present
SELECT nvl(to_char(e.EID), column_value||' Not found') empno from table(sys.odcinumberlist(7369,7370,7566,7555,1))l left outer join emp e on e.EID = l.column_value order by 1
sys.odcinumberlist is the default varray that oracle supplies . If you want to create your own type
CREATE TYPE typ_p is varray (32767) of number
SELECT * from table(typ_p(7369,7370,7566,7555,1 ))
-----------------------------------------------------------------------
To compare null (from 9i onwards)
SELECT 'hi there' FROM DUAL WHERE NULL = NULL;
SELECT 'hi there' FROM DUAL WHERE sys_op_map_nonnull (NULL) = sys_op_map_nonnull (NULL);
SELECT 'hi there' FROM DUAL WHERE nvl(null,'FF')='FF';
select sys_op_map_nonnull(null) from dual; --similat to nvl(null,'FF')
select * from dual where sys_op_map_nonnull(null) = 'FF';
SELECT 'hi there' FROM DUAL WHERE to_char(1||NULL) = to_char(1||NULL);
-----------------------------------------------------------------------
JSP Format Model
To convert date into numbers and words
select to_char(sysdate,'J') "WORDS" from dual;
select to_date(to_char(sysdate,'J'),'J') "WORDS" from dual;
select to_char(to_date( to_char(sysdate,'J') ,'J'), 'JSP') "WORDS" from dual;
----*--------------------------------*-----------------------
To convert numbers into words
select to_char(to_date(873,'J'), 'JSP') as converted_form from dual;
------*-------------------------------------*------------------------
To convert words into numbers
SELECT LEVEL wordasint FROM dual
WHERE TO_CHAR(TO_DATE(LEVEL,'J'), 'JSP') = 'ONE HUNDRED TWENTY-THREE'
CONNECT BY TO_CHAR(TO_DATE(LEVEL-1,'J'),'JSP') != 'ONE HUNDRED TWENTY-THREE'
AND LEVEL < 124; ---FOR 10 g and above
SELECT sp, n
FROM (SELECT 'EIGHTY-SIX THOUSAND THREE HUNDRED NINETY-NINE' sp FROM dual)
MODEL DIMENSION BY (1 dim)
MEASURES (0 n, sp) RULES ITERATE (86400) UNTIL (TO_CHAR(DATE '0001-01-01' +
(ITERATION_NUMBER/86400),'SSSSSSP')=sp[1])
(n[1]=ITERATION_NUMBER);
------------------------------------------------------------------------
select to_char(sysdate,'J') "WORDS" from dual;
select to_date(to_char(sysdate,'J'),'J') "WORDS" from dual;
select to_char(to_date( to_char(sysdate,'J') ,'J'), 'JSP') "WORDS" from dual;
----*--------------------------------*-----------------------
To convert numbers into words
select to_char(to_date(873,'J'), 'JSP') as converted_form from dual;
------*-------------------------------------*------------------------
To convert words into numbers
SELECT LEVEL wordasint FROM dual
WHERE TO_CHAR(TO_DATE(LEVEL,'J'), 'JSP') = 'ONE HUNDRED TWENTY-THREE'
CONNECT BY TO_CHAR(TO_DATE(LEVEL-1,'J'),'JSP') != 'ONE HUNDRED TWENTY-THREE'
AND LEVEL < 124; ---FOR 10 g and above
SELECT sp, n
FROM (SELECT 'EIGHTY-SIX THOUSAND THREE HUNDRED NINETY-NINE' sp FROM dual)
MODEL DIMENSION BY (1 dim)
MEASURES (0 n, sp) RULES ITERATE (86400) UNTIL (TO_CHAR(DATE '0001-01-01' +
(ITERATION_NUMBER/86400),'SSSSSSP')=sp[1])
(n[1]=ITERATION_NUMBER);
------------------------------------------------------------------------
Mar 7, 2009
Query Analyzer
To check whether select or DML statements are correct ,here they will not execute (ie: if we check an insert statement it will not insert particular data into that table ) But DDL statement will get executed during parsing itself .
declare
c integer := dbms_sql.open_cursor;
begin
dbms_sql.parse(c, 'select * from scott.emp', dbms_sql.native);
dbms_sql.close_cursor (c);
end;
declare
c integer := dbms_sql.open_cursor;
begin
dbms_sql.parse(c, 'select * from scott.emp', dbms_sql.native);
dbms_sql.close_cursor (c);
end;
Mar 3, 2009
Oracle Text - Part 6
CTX_DOC
manipulate SQL queries by injecting arbitrary SQL code via the THEMES, GIST, TOKENS, FILTER, HIGHLIGHT, and MARKUP procedures
-----------
Sectioner
The sectioner object is responsible for identifying the containing section(s) for each text unit. Typically, these sections will be predefined HyperText Markup Language (HTML) or eXtensible Markup Language (XML) sections. Optionally,the sectioner can process all tags as sections delimiters.
For example:
<TITLE>XML Handbook</TITLE>. This allows search between tags using the WITHIN operator. Use of the WITHIN is illustrated in the section on XML searching.
manipulate SQL queries by injecting arbitrary SQL code via the THEMES, GIST, TOKENS, FILTER, HIGHLIGHT, and MARKUP procedures
-----------
Sectioner
The sectioner object is responsible for identifying the containing section(s) for each text unit. Typically, these sections will be predefined HyperText Markup Language (HTML) or eXtensible Markup Language (XML) sections. Optionally,the sectioner can process all tags as sections delimiters.
For example:
<TITLE>XML Handbook</TITLE>. This allows search between tags using the WITHIN operator. Use of the WITHIN is illustrated in the section on XML searching.
Mar 2, 2009
Oracle Text - Part 5
Generating XML Output
The INDEX_STATS procedure supports both formatted text and XML output.The following code
creates the INDEX_STATS report in text format:
-- Table to store our report
CREATE TABLE index_report (id NUMBER(10), report CLOB);
DECLARE
v_report CLOB := null;
BEGIN
CTX_REPORT.INDEX_STATS(index_name => 'SONG_INDEX',
report => v_report,part_name => NULL,frag_stats => NULL,
list_size => 20,report_format => NULL);
INSERT INTO index_report (id, report) VALUES (1, v_report);
COMMIT;
DBMS_LOB.FREETEMPORARY(v_report);
END;
/
Then output can be viewed:
SELECT report FROM index_report WHERE id = 1;
To find out the size of the index, we can use the function CTX_REPORT.INDEX_SIZE. This is a function returning a CLOB.
select ctx_report.index_size('SONG_INDEX') from dual;
for a XML report :
SQL> select ctx_report.index_size('SONG_INDEX', null, 'XML') from dual;
This will give us a heap of XML output, including sizes for each object.
Here's a section of the output:
<SIZE_OBJECT_NAME> text_user.SYS_IL0000051565C00006$$
</SIZE_OBJECT_NAME>
<SIZE_OBJECT_TYPE> INDEX (LOB)
</SIZE_OBJECT_TYPE>
<SIZE_TABLE_NAME> text_user.DR$TI$I
</SIZE_TABLE_NAME>
<SIZE_TABLESPACE_NAME> USERS
</SIZE_TABLESPACE_NAME>
<SIZE_BLOCKS_ALLOCATED> 8
</SIZE_BLOCKS_ALLOCATED>
<SIZE_BLOCKS_USED> 4
</SIZE_BLOCKS_USED>
<SIZE_BYTES_ALLOCATED> 65536
</SIZE_BYTES_ALLOCATED>
<SIZE_BYTES_USED> 32768
</SIZE_BYTES_USED>
</SIZE_OBJECT>
<SIZE_OBJECT>
selecting a CLOB, force it into an XMLTYPE value:
select xmltype(ctx_report.index_size('SONG_INDEX', null, 'XML')) from dual;
select extract(xmltype(ctx_report.index_size('SONG_INDEX', null, 'XML')), '//SIZE_OBJECT') from dual;
We're now using the XML DB "extract" function to fetch all of the XML within tags. The syntax '//SIZE_OBJECT' is an XPATH expression meaning "all the XML within a SIZE_OBJECT element anywhere below the root element".the reader is encouraged to look at the tutorial at w3Schools.
select extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT') from dual;
Now specify that only information from the table $I is want . this is done with
within a predicate the xpath expression:
select extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT[SIZE_OBJECT_NAME="text_user.DR$TI$I"]') from dual;
The size in bytes can be get by adding the XPATH expression:
select extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT[SIZE_OBJECT_NAME="text_user.DR$TI$I"]/SIZE_BYTES_USED') from dual;
To avoid tags. There's two ways of doing this 1) the text() function within the XPATH, 2) use extractValue rather than extract.
select extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT[SIZE_OBJECT_NAME="text_user.DR$TI$I"]/SIZE_BYTES_USED/text()') as "Table Size" from dual;
select extractValue(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')), '//SIZE_OBJECT[SIZE_OBJECT_NAME="text_user.DR$TI$I"]/SIZE_BYTES_USED')as "Table Size" from dual;
For fetching ALL the sizes, perhaps to add them together to get a summary XMLSequence can use,which returns a collection of XMLType values. This function can use in a TABLE clause to unnest the collection values into multiple rows. Now that we're generating a "table", we no longer need to reference DUAL.
To get just the sizes:
select * from table(xmlsequence( extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT/SIZE_BYTES_USED')));
To get all the object info, one object per row:
select * from table(xmlsequence( extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')), '//SIZE_OBJECT')));
Processing information into individual values:
select extractValue(Column_Value, '/SIZE_OBJECT/SIZE_OBJECT_NAME') as "Name",
extractValue(Column_Value, '/SIZE_OBJECT/SIZE_TABLESPACE_NAME') as "Tablespace",
extractValue(Column_Value, '/SIZE_OBJECT/SIZE_BYTES_USED') as "Bytes"
from table(xmlsequence(extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT')));
To get sum of all the sizes to get an aggragate total size of all objects
used in the index.
select sum(extractValue(Column_Value, '/SIZE_OBJECT/SIZE_BYTES_USED')) "Total"
from table(xmlsequence(extract(xmltype(replace(ctx_report.index_size('ti', null, 'XML'),chr(10),'')),'//SIZE_OBJECT')));
INDEX_STATS
Most of the CTX_REPORT procedures have two forms - a function which returns a CLOB (as done above)and an alternate form which requires to pass in a CLOB to be populated. One procedure - INDEX_STATS - does not have a function version. This is because it needs to do a full table scan of the main index table, which is likely to take some time.Therefore when calling INDEX_STATS it is needed to go about things a little differently. First create a table with an XMLType column. Then call a PL/SQL block which passes a temporary CLOB to CTX_REPORT, and then inserts that CLOB into the XMLType column. Then various XML operations can perform on that table.
create table output(report XMLType);
declare
tlob clob;
begin
ctx_report.index_stats(index_name=>'ti', report=>tlob,
list_size=>20, report_format=>'XML');
insert into output values (xmlType (replace(tlob,chr(10),'')) );
commit;
dbms_lob.freetemporary(tlob);
end;
/
There is a single row in table OUTPUT, which contains XML report. First well get the
estimated row fragmentation:
select extractValue(report,'//STAT_STATISTIC[@NAME="estimated row fragmentation"]')
as "Fragmentation" from output;
Now get the top three most frequent tokens.
using the position function:
select extract(value(d), '//STAT_TOKEN_TEXT')
from output, table(xmlsequence(extract(report,'/CTXREPORT/INDEX_STATS/STAT_TOKEN_STATS/STAT_TOKEN_LIST[@NAME="most frequent tokens"]/
STAT_TOKEN[position()<4]'))) d; Conclusion
The XML output mode of CTX_REPORT allows powerful manipulation of index information. In order to make full use of these,a good understanding of the XML features of the Oracle database, such as extract, extractValue, XMLSequence, and of XPATH syntax in general is needed.With the use of XML exploding within the data processing world, such an understanding is likely to be very useful in the future.
The INDEX_STATS procedure supports both formatted text and XML output.The following code
creates the INDEX_STATS report in text format:
-- Table to store our report
CREATE TABLE index_report (id NUMBER(10), report CLOB);
DECLARE
v_report CLOB := null;
BEGIN
CTX_REPORT.INDEX_STATS(index_name => 'SONG_INDEX',
report => v_report,part_name => NULL,frag_stats => NULL,
list_size => 20,report_format => NULL);
INSERT INTO index_report (id, report) VALUES (1, v_report);
COMMIT;
DBMS_LOB.FREETEMPORARY(v_report);
END;
/
Then output can be viewed:
SELECT report FROM index_report WHERE id = 1;
To find out the size of the index, we can use the function CTX_REPORT.INDEX_SIZE. This is a function returning a CLOB.
select ctx_report.index_size('SONG_INDEX') from dual;
for a XML report :
SQL> select ctx_report.index_size('SONG_INDEX', null, 'XML') from dual;
This will give us a heap of XML output, including sizes for each object.
Here's a section of the output:
<SIZE_OBJECT_NAME> text_user.SYS_IL0000051565C00006$$
</SIZE_OBJECT_NAME>
<SIZE_OBJECT_TYPE> INDEX (LOB)
</SIZE_OBJECT_TYPE>
<SIZE_TABLE_NAME> text_user.DR$TI$I
</SIZE_TABLE_NAME>
<SIZE_TABLESPACE_NAME> USERS
</SIZE_TABLESPACE_NAME>
<SIZE_BLOCKS_ALLOCATED> 8
</SIZE_BLOCKS_ALLOCATED>
<SIZE_BLOCKS_USED> 4
</SIZE_BLOCKS_USED>
<SIZE_BYTES_ALLOCATED> 65536
</SIZE_BYTES_ALLOCATED>
<SIZE_BYTES_USED> 32768
</SIZE_BYTES_USED>
</SIZE_OBJECT>
<SIZE_OBJECT>
selecting a CLOB, force it into an XMLTYPE value:
select xmltype(ctx_report.index_size('SONG_INDEX', null, 'XML')) from dual;
select extract(xmltype(ctx_report.index_size('SONG_INDEX', null, 'XML')), '//SIZE_OBJECT') from dual;
We're now using the XML DB "extract" function to fetch all of the XML within
select extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT') from dual;
Now specify that only information from the table $I is want . this is done with
within a predicate the xpath expression:
select extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT[SIZE_OBJECT_NAME="text_user.DR$TI$I"]') from dual;
The size in bytes can be get by adding the XPATH expression:
select extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT[SIZE_OBJECT_NAME="text_user.DR$TI$I"]/SIZE_BYTES_USED') from dual;
To avoid tags. There's two ways of doing this 1) the text() function within the XPATH, 2) use extractValue rather than extract.
select extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT[SIZE_OBJECT_NAME="text_user.DR$TI$I"]/SIZE_BYTES_USED/text()') as "Table Size" from dual;
select extractValue(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')), '//SIZE_OBJECT[SIZE_OBJECT_NAME="text_user.DR$TI$I"]/SIZE_BYTES_USED')as "Table Size" from dual;
For fetching ALL the sizes, perhaps to add them together to get a summary XMLSequence can use,which returns a collection of XMLType values. This function can use in a TABLE clause to unnest the collection values into multiple rows. Now that we're generating a "table", we no longer need to reference DUAL.
To get just the sizes:
select * from table(xmlsequence( extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT/SIZE_BYTES_USED')));
To get all the object info, one object per row:
select * from table(xmlsequence( extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')), '//SIZE_OBJECT')));
Processing information into individual values:
select extractValue(Column_Value, '/SIZE_OBJECT/SIZE_OBJECT_NAME') as "Name",
extractValue(Column_Value, '/SIZE_OBJECT/SIZE_TABLESPACE_NAME') as "Tablespace",
extractValue(Column_Value, '/SIZE_OBJECT/SIZE_BYTES_USED') as "Bytes"
from table(xmlsequence(extract(xmltype(replace(ctx_report.index_size('SONG_INDEX', null, 'XML'),chr(10),'')),'//SIZE_OBJECT')));
To get sum of all the sizes to get an aggragate total size of all objects
used in the index.
select sum(extractValue(Column_Value, '/SIZE_OBJECT/SIZE_BYTES_USED')) "Total"
from table(xmlsequence(extract(xmltype(replace(ctx_report.index_size('ti', null, 'XML'),chr(10),'')),'//SIZE_OBJECT')));
INDEX_STATS
Most of the CTX_REPORT procedures have two forms - a function which returns a CLOB (as done above)and an alternate form which requires to pass in a CLOB to be populated. One procedure - INDEX_STATS - does not have a function version. This is because it needs to do a full table scan of the main index table, which is likely to take some time.Therefore when calling INDEX_STATS it is needed to go about things a little differently. First create a table with an XMLType column. Then call a PL/SQL block which passes a temporary CLOB to CTX_REPORT, and then inserts that CLOB into the XMLType column. Then various XML operations can perform on that table.
create table output(report XMLType);
declare
tlob clob;
begin
ctx_report.index_stats(index_name=>'ti', report=>tlob,
list_size=>20, report_format=>'XML');
insert into output values (xmlType (replace(tlob,chr(10),'')) );
commit;
dbms_lob.freetemporary(tlob);
end;
/
There is a single row in table OUTPUT, which contains XML report. First well get the
estimated row fragmentation:
select extractValue(report,'//STAT_STATISTIC[@NAME="estimated row fragmentation"]')
as "Fragmentation" from output;
Now get the top three most frequent tokens.
using the position function:
select extract(value(d), '//STAT_TOKEN_TEXT')
from output, table(xmlsequence(extract(report,'/CTXREPORT/INDEX_STATS/STAT_TOKEN_STATS/STAT_TOKEN_LIST[@NAME="most frequent tokens"]/
STAT_TOKEN[position()<4]'))) d; Conclusion
The XML output mode of CTX_REPORT allows powerful manipulation of index information. In order to make full use of these,a good understanding of the XML features of the Oracle database, such as extract, extractValue, XMLSequence, and of XPATH syntax in general is needed.With the use of XML exploding within the data processing world, such an understanding is likely to be very useful in the future.
Oracle Text - Part 4
Progressive Relaxation is a new technique for text searching, available with Oracle 10g.
It assumes a basic working knowledge of Oracle Text, such as the operators used
in query expressions.When Would Use It?
First, let's consider a search scenario.
You have a web site selling books. A user searches for "Michael Crichton" in the "search author" box. OK, easy enough. You do the search, and return the top 10 hits (or whatever) that match the search criteria.
But what if the user mis-spells the firstname, and searches for "Michel Crichton"? In this case, a good strategy for handling this might be to find the top 10 hits from these searches:
1. Any books where the author is exactly "Michel Crichton"
2. Any books containing a fuzzy match of each word, in the right order
3. Any books having either exact word
4. Any books having a fuzzy match of either word.
Of course we can do this in a search like
select book_id from books where contains (author, '(michel crichton) OR (?michel ?crichton) OR (michel OR crichton) OR (?michel OR ?crichton)
But there are two problems with this search:
1. From the user's point of view, hits which are a poor match will be mixed in with hits which are a good match. The user wants to see good matches displayed first.
2. From the system's point of view, the search is inefficient. Even if there were plenty of hits for exactly "Michel Crichton", it would still have to do all the work of the fuzzy expansions and fetch data for all the rows which satisfy the query.
An alternative is to run four separate queries. This way, we can do the exact search first, and then only run the queries with more relaxed criteria if they are needed to get enough hits for the results page.
But apart from the inefficiency of (potentially) running multiple queries, we need to de-duplicate the results. The "relaxed" queries will in many cases hit the rows returned by the exact queries. To avoid duplicates in the result set, the application must screen these hits out, a potentially expensive task in terms of programming and maintenance,if not raw performance.
To solve this problem, Oracle Text in Oracle Database 10g introduces "progressive relaxation".This allows you to specify the different searches to run, and Oracle will run each in turn,returning de-duplicated results until the application stops fetching hits.
The scores returned are manipulated such that if you order by score
Benefits
The benefits of progressive relaxtion is that an application developer can specify operations to be applied to a user query in a declarative manner. It is not necessary to parse the query and apply operators to each search term - the developer just specifies what options should be applied to each term, and how they should be combined (eg AND or OR)
The application also benefits from automatic de-duplication of results at a very early stage in the query (before docid to rowid translation) which is much more efficient than doing it at the final stage, as you would have to if you were running multiple queries.
Query Templates
The actual implementation of progressive relaxation is via the query template mechanism. If you have not come across this before, don't worry - it's quite straightforward and the examples should make it clear. Basically a query template is an XML fragment that is used in the CONTAINS clause in place of a simple query string.
There are some other things that you can do with query templates, such as specifying
language, query grammars and scoring options, but we won't be covering them here.
So - on to our first example:
create table mybooks (title varchar2(20), author varchar2(20));
insert into mybooks values ('Consider the Lillies', 'Ian Crichton Smith');
insert into mybooks values ('Sphere', 'Michael Crichton');
insert into mybooks values ('Stupid White Men', 'Michael Moore');
insert into mybooks values ('Lonely Day', 'Michaela Criton');
insert into mybooks values ('How to Teach Poetry', 'Michaela Morgan');
create index auth_idx on mybooks (author) indextype is ctxsys.context;
SELECT score(1), title, author FROM mybooks WHERE CONTAINS (author, '
<query>
<textquery>
<progression>
<seq>michael crichton </seq>
<seq>?michael ?crichton </seq>
<seq>michael OR crichton </seq>
<seq>?michael OR ?crichton </seq>
</progression>
</textquery>
</query>', 1) > 0 ORDER BY score(1) DESC;
The output of this query is:
SCORE(1) TITLE AUTHOR
---------- -------------------- --------------------
76 Sphere Michael Crichton
51 Lonely Day Michaela Criton
26 Stupid White Men Michael Moore
26 Consider the Lillies Ian Crichton Smith
1 How to Teach Poetry Michaela Morgan
It can see that the first line is an exact match, according to the first entry in our progression sequence. The second line corresponds to a fuzzy match of each term in order - our second criteria. The third and fourth rows come from the exact "micheal OR chrichton" and finally the last row has a single match which is a fuzzy hit on one of the terms.
Obviously in this example, it is fetching all the rows, so there is no major advantage in using progressive relaxation. We can limit it to only return the first two hits, using a PL/SQL cursor:
set serveroutput on format wrapped
declare
max_rows integer := 2;
counter integer := 0;
begin
-- do the headings
dbms_output.put_line(rpad('Score', 8)||rpad('Title', 20)||rpad('Author', 20));
dbms_output.put_line(rpad('-----', 8)||rpad('-----', 20)||rpad('------', 20));
-- loop for the required number of rows
for c in (select score(1) scr, title, author from mybooks where contains (author, '
<query>
<textquery>
<progression>
<seq>michael crichton </seq>
<seq>?michael ?crichton </seq>
<seq>michael OR crichton </seq>
<seq>?michael OR ?crichton </seq>
</progression>
</textquery>
</query>', 1) > 0) loop
dbms_output.put_line(rpad(c.scr, 8)||rpad(c.title, 20)||rpad(c.author, 20));
counter := counter + 1;
exit when counter >= max_rows;
end loop;
end;
/
The output from this is
Score Title Author
----- ----- ------
76 Sphere Michael Crichton
51 Lonely Day Michaela Criton
Now theres one more feature an application designer might want. And thats to
stop the search after it has evaluated the first successful search criteria. So in our example, if we get one or more hits on exactly "michael chrichton", we dont want to try any of the other searches. If the exact search fails, we want to try the others only until one of them returns one or more rows.
Theres (currently) no way to do this as part of the query template syntax.However, it is possible to do this at the application level by looking at the scores returned using PLSQL
Score Title Author
----- ----- ------
76 Sphere Michael Crichton
51 Lonely Day Michaela Criton
26 Stupid White Men Michael Moore
26 Consider the Lillies Ian Crichton Smith
1 How to Teach Poetry Michaela Morgan
Now, given that the maximum score of a text query is 100, and that we had four steps in our search, we might be able to notice something here. Specifically, any match on the first step will always score in the top quarter of the possible results - 76% to 100%. The next step will score in the range 51-75%, the next 26-50%, and the final step 1-25%. If we had had five steps in our query, the scores would have been in the ranges 81-100%, 61-80%, 41-60%, 21-40% and 1-20%.
So in order to stop our results after the first valid search, we need to detect the score crossing one of these boundaries. In order to do this we MUST know in advance how many stepsthere are. The PL/SQL for all this is a little more tricky than before:
declare
max_rows integer := 2;
counter integer := 0;
number_of_steps integer := 4;
score_range_size integer; -- 33 for 3 steps, 25 for 4, 20 for 5 etc
this_score_group integer; -- final step is 1, penultimate step is 2 ...
last_score_group integer := 0; -- to compare change
begin
-- do the headings
dbms_output.put_line(rpad('Score', 8)||rpad('Title', 20)||rpad('Author', 20));
dbms_output.put_line(rpad('-----', 8)||rpad('-----', 20)||rpad('------', 20));
for c in (select score(1) scr, title, author from mybooks where contains (author, '
<query>
<textquery>
<progression>
<seq>michael crichton </seq>
<seq>?michael ?crichton </seq>
<seq>michael OR crichton </seq>
<seq>?michael OR ?crichton </seq>
</progression>
</textquery>
</query>', 1) > 0) loop
score_range_size := 100/number_of_steps;
this_score_group := c.scr/score_range_size;
exit when this_score_group < last_score_group;
last_score_group := this_score_group;
dbms_output.put_line(rpad(c.scr , 8)||rpad(c.title, 20)||rpad(c.author, 20));
counter := counter + 1;
exit when counter >= max_rows;
end loop;
end;
/
The output from this is:
Score Title Author
----- ----- ------
76 Sphere Michael Crichton
We could add a new, stricter step (remembering to increase the number_of_steps variable).This won't actually find anything but will demonstrate that the procedure continues until it does find at least one row:
number of steps number := 5;
...
<query>
<textquery>
<progression>
<seq>michael crichton </seq>
<seq>?michael ?crichton </seq>
<seq>michael OR crichton </seq>
<seq>?michael OR ?crichton </seq>
</progression>
</textquery>
</query>
and output would be:
Score Title Author
----- ----- ------
61 Sphere Michael Crichton
there is a simplification which makes life easier for the application developer.
Generating the full syntax above can be complicated to program. So there is a "shorthand" syntax, known as a "query rewrite template":
<query>
<textquery> michael crichton
<progression>
<seq><rewrite>transform((TOKENS, "{", "}", " "))</rewrite></seq>
<seq><rewrite>transform((TOKENS, "?{", "}", " "))</rewrite></seq>
<seq><rewrite>transform((TOKENS, "{", "}", "OR"))</rewrite></seq>
<seq><rewrite>transform((TOKENS, "?{", "}", "OR"))</rewrite></seq>
</progression>
</textquery>
</query>
This will generate the same four-step syntax as used above. The arguments after TOKENS are as follows:
* Prefix - what to put before each token
* Suffix - what to put after each token
* Connector - an operator to link each token. Space causes a phrase search.
It is usually a good idea to surround each term with braces "{}", in case the user has entered a reserved word like STEM or NT. Beware, though, that adding a wild card after a brace can have strange effects - {dog}% is not the same as dog%.
It assumes a basic working knowledge of Oracle Text, such as the operators used
in query expressions.When Would Use It?
First, let's consider a search scenario.
You have a web site selling books. A user searches for "Michael Crichton" in the "search author" box. OK, easy enough. You do the search, and return the top 10 hits (or whatever) that match the search criteria.
But what if the user mis-spells the firstname, and searches for "Michel Crichton"? In this case, a good strategy for handling this might be to find the top 10 hits from these searches:
1. Any books where the author is exactly "Michel Crichton"
2. Any books containing a fuzzy match of each word, in the right order
3. Any books having either exact word
4. Any books having a fuzzy match of either word.
Of course we can do this in a search like
select book_id from books where contains (author, '(michel crichton) OR (?michel ?crichton) OR (michel OR crichton) OR (?michel OR ?crichton)
But there are two problems with this search:
1. From the user's point of view, hits which are a poor match will be mixed in with hits which are a good match. The user wants to see good matches displayed first.
2. From the system's point of view, the search is inefficient. Even if there were plenty of hits for exactly "Michel Crichton", it would still have to do all the work of the fuzzy expansions and fetch data for all the rows which satisfy the query.
An alternative is to run four separate queries. This way, we can do the exact search first, and then only run the queries with more relaxed criteria if they are needed to get enough hits for the results page.
But apart from the inefficiency of (potentially) running multiple queries, we need to de-duplicate the results. The "relaxed" queries will in many cases hit the rows returned by the exact queries. To avoid duplicates in the result set, the application must screen these hits out, a potentially expensive task in terms of programming and maintenance,if not raw performance.
To solve this problem, Oracle Text in Oracle Database 10g introduces "progressive relaxation".This allows you to specify the different searches to run, and Oracle will run each in turn,returning de-duplicated results until the application stops fetching hits.
The scores returned are manipulated such that if you order by score
Benefits
The benefits of progressive relaxtion is that an application developer can specify operations to be applied to a user query in a declarative manner. It is not necessary to parse the query and apply operators to each search term - the developer just specifies what options should be applied to each term, and how they should be combined (eg AND or OR)
The application also benefits from automatic de-duplication of results at a very early stage in the query (before docid to rowid translation) which is much more efficient than doing it at the final stage, as you would have to if you were running multiple queries.
Query Templates
The actual implementation of progressive relaxation is via the query template mechanism. If you have not come across this before, don't worry - it's quite straightforward and the examples should make it clear. Basically a query template is an XML fragment that is used in the CONTAINS clause in place of a simple query string.
There are some other things that you can do with query templates, such as specifying
language, query grammars and scoring options, but we won't be covering them here.
So - on to our first example:
create table mybooks (title varchar2(20), author varchar2(20));
insert into mybooks values ('Consider the Lillies', 'Ian Crichton Smith');
insert into mybooks values ('Sphere', 'Michael Crichton');
insert into mybooks values ('Stupid White Men', 'Michael Moore');
insert into mybooks values ('Lonely Day', 'Michaela Criton');
insert into mybooks values ('How to Teach Poetry', 'Michaela Morgan');
create index auth_idx on mybooks (author) indextype is ctxsys.context;
SELECT score(1), title, author FROM mybooks WHERE CONTAINS (author, '
<query>
<textquery>
<progression>
<seq>michael crichton </seq>
<seq>?michael ?crichton </seq>
<seq>michael OR crichton </seq>
<seq>?michael OR ?crichton </seq>
</progression>
</textquery>
</query>', 1) > 0 ORDER BY score(1) DESC;
The output of this query is:
SCORE(1) TITLE AUTHOR
---------- -------------------- --------------------
76 Sphere Michael Crichton
51 Lonely Day Michaela Criton
26 Stupid White Men Michael Moore
26 Consider the Lillies Ian Crichton Smith
1 How to Teach Poetry Michaela Morgan
It can see that the first line is an exact match, according to the first
Obviously in this example, it is fetching all the rows, so there is no major advantage in using progressive relaxation. We can limit it to only return the first two hits, using a PL/SQL cursor:
set serveroutput on format wrapped
declare
max_rows integer := 2;
counter integer := 0;
begin
-- do the headings
dbms_output.put_line(rpad('Score', 8)||rpad('Title', 20)||rpad('Author', 20));
dbms_output.put_line(rpad('-----', 8)||rpad('-----', 20)||rpad('------', 20));
-- loop for the required number of rows
for c in (select score(1) scr, title, author from mybooks where contains (author, '
<query>
<textquery>
<progression>
<seq>michael crichton </seq>
<seq>?michael ?crichton </seq>
<seq>michael OR crichton </seq>
<seq>?michael OR ?crichton </seq>
</progression>
</textquery>
</query>', 1) > 0) loop
dbms_output.put_line(rpad(c.scr, 8)||rpad(c.title, 20)||rpad(c.author, 20));
counter := counter + 1;
exit when counter >= max_rows;
end loop;
end;
/
The output from this is
Score Title Author
----- ----- ------
76 Sphere Michael Crichton
51 Lonely Day Michaela Criton
Now theres one more feature an application designer might want. And thats to
stop the search after it has evaluated the first successful search criteria. So in our example, if we get one or more hits on exactly "michael chrichton", we dont want to try any of the other searches. If the exact search fails, we want to try the others only until one of them returns one or more rows.
Theres (currently) no way to do this as part of the query template syntax.However, it is possible to do this at the application level by looking at the scores returned using PLSQL
Score Title Author
----- ----- ------
76 Sphere Michael Crichton
51 Lonely Day Michaela Criton
26 Stupid White Men Michael Moore
26 Consider the Lillies Ian Crichton Smith
1 How to Teach Poetry Michaela Morgan
Now, given that the maximum score of a text query is 100, and that we had four
So in order to stop our results after the first valid search, we need to detect the score crossing one of these boundaries. In order to do this we MUST know in advance how many stepsthere are. The PL/SQL for all this is a little more tricky than before:
declare
max_rows integer := 2;
counter integer := 0;
number_of_steps integer := 4;
score_range_size integer; -- 33 for 3 steps, 25 for 4, 20 for 5 etc
this_score_group integer; -- final step is 1, penultimate step is 2 ...
last_score_group integer := 0; -- to compare change
begin
-- do the headings
dbms_output.put_line(rpad('Score', 8)||rpad('Title', 20)||rpad('Author', 20));
dbms_output.put_line(rpad('-----', 8)||rpad('-----', 20)||rpad('------', 20));
for c in (select score(1) scr, title, author from mybooks where contains (author, '
<query>
<textquery>
<progression>
<seq>michael crichton </seq>
<seq>?michael ?crichton </seq>
<seq>michael OR crichton </seq>
<seq>?michael OR ?crichton </seq>
</progression>
</textquery>
</query>', 1) > 0) loop
score_range_size := 100/number_of_steps;
this_score_group := c.scr/score_range_size;
exit when this_score_group < last_score_group;
last_score_group := this_score_group;
dbms_output.put_line(rpad(c.scr , 8)||rpad(c.title, 20)||rpad(c.author, 20));
counter := counter + 1;
exit when counter >= max_rows;
end loop;
end;
/
The output from this is:
Score Title Author
----- ----- ------
76 Sphere Michael Crichton
We could add a new, stricter step (remembering to increase the number_of_steps variable).This won't actually find anything but will demonstrate that the procedure continues until it does find at least one row:
number of steps number := 5;
...
<query>
<textquery>
<progression>
<seq>michael crichton </seq>
<seq>?michael ?crichton </seq>
<seq>michael OR crichton </seq>
<seq>?michael OR ?crichton </seq>
</progression>
</textquery>
</query>
and output would be:
Score Title Author
----- ----- ------
61 Sphere Michael Crichton
there is a simplification which makes life easier for the application developer.
Generating the full syntax above can be complicated to program. So there is a "shorthand" syntax, known as a "query rewrite template":
<query>
<textquery> michael crichton
<progression>
<seq><rewrite>transform((TOKENS, "{", "}", " "))</rewrite></seq>
<seq><rewrite>transform((TOKENS, "?{", "}", " "))</rewrite></seq>
<seq><rewrite>transform((TOKENS, "{", "}", "OR"))</rewrite></seq>
<seq><rewrite>transform((TOKENS, "?{", "}", "OR"))</rewrite></seq>
</progression>
</textquery>
</query>
This will generate the same four-step syntax as used above. The arguments after TOKENS are as follows:
* Prefix - what to put before each token
* Suffix - what to put after each token
* Connector - an operator to link each token. Space causes a phrase search.
It is usually a good idea to surround each term with braces "{}", in case the user has entered a reserved word like STEM or NT. Beware, though, that adding a wild card after a brace can have strange effects - {dog}% is not the same as dog%.
Oracle Text - Part 3
CTXCAT indexes work best when text is in "small chunks" - maybe a couple of lines maximum - and searches need to restrict and/or sort the result set according to certain structured criteria - usually numbers or dates.
For example,consider an on-line auction site. Each item for sale has a short
description, a current bid price and dates for the start and end of the auction. A
user might want to see all the records with a
current bid price less than $500. Since he's particularly interested in new items, he wants the results sorted by auction start time.
Such a search would be fairly inefficient using a normal CONTEXT index. The kernel would have to find all the records that matched the text search, then restrict the set to those with the correct price (which requires the use of a different index), and then sort the results using a third index.
By including structured information such as price and date within the CTXCAT index, we are able to make this search very much more efficient.When is a CTXCAT index NOT suitable?
The query language with CTXCAT is considerably simpler than for CONTEXT indexes. Basically, you can search for phrases and words (with wild cards if required), using AND and OR operators. If your application needs more complex text retrieval featurs - such as stemming, thesaurus, fuzzy matching and so on, you should be using a CONTEXT index.
There are also differences in the time and space needed to create the index. CTXCAT indexes take quite a bit longer to create - and use considerably more disk space - than CONTEXT indexes. If you are tight on disk space, you should consider carefully whether CTXCAT indexes are appropriate for you.Any other differences?
Yes - in DML processing (updates, inserts and deletes).CTXCAT indexes are transactional.Where a CONTEXT index uses a "deferred indexing" method - CTXCAT indexes work much more like a normal (b-tree) index. When you commit changes, all necesary changes to the CTXCAT indexes take place before the commit returns
CREATE INDEX indexname ON table(column) INDEXTYPE IS CTXCAT;
EG:
create table auction (
item_id NUMBER PRIMARY KEY, -- auction item identifier
item_desc VARCHAR2(80), -- free-form item description
price NUMBER, -- current price of the item
start_time DATE -- end time of the auction
end_time DATE -- end time of the auction
)
A CTXCAT index (like a CONTEXT index) is a "domain" index. Therefore it supports the
"PARAMETERS" clause. A number of possible parameter settings are shared with CONTEXT indexes.These are: LEXER, MEMORY, STOPLIST, STORAGE and WORDLIST (no other CONTEXT parameters are supported). Howevwer, the most important parameter is a new one: INDEX SET.
INDEX SET defines the structured columns that are to be included in the CTXCAT index. if I want to create an index on the item_desc column, but I need to be able to limit my search results by price, and sort by start_time. I do this by creating a new INDEX SET, and adding the structured columns to it.CTX_DDL package allow to do this:
ctx_ddl.create_index_set('auction_set');
ctx_ddl.add_index ('auction_set', 'price');
ctx_ddl.add_index ('auction_set', 'start_time');
Note that the item_desc column is NOT part of the INDEX SET. item_desc is only mentioned when we come to create the actual index:
CREATE INDEX auction_index ON auction (item_desc)
INDEXTYPE IS CTXCAT
PARAMETERS ('INDEX SET auction_set');
how to search ?
By using the CATSEARCH operator instead of the CONTAINS operator used for
a CONTEXT index.If i want to find all auction items which contains the words "toy" and "dog" but not
the phrase "live animal":
SELECT item_id, item_desc FROM auction
WHERE CATSEARCH (item_desc, '(toy dog) | "live animal"', null) > 0;
A few points to note:
* ANDed terms do not need the word AND or even an "&" operator. AND is assumed between
any adjacent terms.
* NOT is represented by "|" (OR, not used here, is represented by "|")
* Parentheses can be used to group terms
* Double quotes are used to surround a phrase (otherwise "live animal" would have been
read as "live AND animal".
The "null" in the query above is a placeholder for a structured clause. There is no default -
if no structured clause is provided "null" Must be used here.
The structured clause allows to restrict, or sort,the results.the query can be extended
above to find only items costing less than $100,
WHERE CATSEARCH (item_desc, '(toy dog) | "live animal"', 'price < 100') > 0
and want to find the results with the newest items first
WHERE CATSEARCH (item_desc, '(toy dog) | "live animal"',
'price < 100 order by start_time desc') > 0
--------------------------------------------
It is worth noting that the creation of the B-Tree indexes will be considerably quicker if the SORT_AREA_SIZE kernel parameter is increased. The default is 64K - a very low figure. Increasing this to 1MB will have a very significant effect - by doing this index-creation times reduce by a factor of 10 . However note the specified amount of memory will be used by EVERY process connecting, so great care should be taken with this parameter if the database is shared with many other users. It might be possible to increase it just for index creation, then reduce it later.
For example,consider an on-line auction site. Each item for sale has a short
description, a current bid price and dates for the start and end of the auction. A
user might want to see all the records with a
current bid price less than $500. Since he's particularly interested in new items, he wants the results sorted by auction start time.
Such a search would be fairly inefficient using a normal CONTEXT index. The kernel would have to find all the records that matched the text search, then restrict the set to those with the correct price (which requires the use of a different index), and then sort the results using a third index.
By including structured information such as price and date within the CTXCAT index, we are able to make this search very much more efficient.When is a CTXCAT index NOT suitable?
The query language with CTXCAT is considerably simpler than for CONTEXT indexes. Basically, you can search for phrases and words (with wild cards if required), using AND and OR operators. If your application needs more complex text retrieval featurs - such as stemming, thesaurus, fuzzy matching and so on, you should be using a CONTEXT index.
There are also differences in the time and space needed to create the index. CTXCAT indexes take quite a bit longer to create - and use considerably more disk space - than CONTEXT indexes. If you are tight on disk space, you should consider carefully whether CTXCAT indexes are appropriate for you.Any other differences?
Yes - in DML processing (updates, inserts and deletes).CTXCAT indexes are transactional.Where a CONTEXT index uses a "deferred indexing" method - CTXCAT indexes work much more like a normal (b-tree) index. When you commit changes, all necesary changes to the CTXCAT indexes take place before the commit returns
CREATE INDEX indexname ON table(column) INDEXTYPE IS CTXCAT;
EG:
create table auction (
item_id NUMBER PRIMARY KEY, -- auction item identifier
item_desc VARCHAR2(80), -- free-form item description
price NUMBER, -- current price of the item
start_time DATE -- end time of the auction
end_time DATE -- end time of the auction
)
A CTXCAT index (like a CONTEXT index) is a "domain" index. Therefore it supports the
"PARAMETERS" clause. A number of possible parameter settings are shared with CONTEXT indexes.These are: LEXER, MEMORY, STOPLIST, STORAGE and WORDLIST (no other CONTEXT parameters are supported). Howevwer, the most important parameter is a new one: INDEX SET.
INDEX SET defines the structured columns that are to be included in the CTXCAT index. if I want to create an index on the item_desc column, but I need to be able to limit my search results by price, and sort by start_time. I do this by creating a new INDEX SET, and adding the structured columns to it.CTX_DDL package allow to do this:
ctx_ddl.create_index_set('auction_set');
ctx_ddl.add_index ('auction_set', 'price');
ctx_ddl.add_index ('auction_set', 'start_time');
Note that the item_desc column is NOT part of the INDEX SET. item_desc is only mentioned when we come to create the actual index:
CREATE INDEX auction_index ON auction (item_desc)
INDEXTYPE IS CTXCAT
PARAMETERS ('INDEX SET auction_set');
how to search ?
By using the CATSEARCH operator instead of the CONTAINS operator used for
a CONTEXT index.If i want to find all auction items which contains the words "toy" and "dog" but not
the phrase "live animal":
SELECT item_id, item_desc FROM auction
WHERE CATSEARCH (item_desc, '(toy dog) | "live animal"', null) > 0;
A few points to note:
* ANDed terms do not need the word AND or even an "&" operator. AND is assumed between
any adjacent terms.
* NOT is represented by "|" (OR, not used here, is represented by "|")
* Parentheses can be used to group terms
* Double quotes are used to surround a phrase (otherwise "live animal" would have been
read as "live AND animal".
The "null" in the query above is a placeholder for a structured clause. There is no default -
if no structured clause is provided "null" Must be used here.
The structured clause allows to restrict, or sort,the results.the query can be extended
above to find only items costing less than $100,
WHERE CATSEARCH (item_desc, '(toy dog) | "live animal"', 'price < 100') > 0
and want to find the results with the newest items first
WHERE CATSEARCH (item_desc, '(toy dog) | "live animal"',
'price < 100 order by start_time desc') > 0
--------------------------------------------
It is worth noting that the creation of the B-Tree indexes will be considerably quicker if the SORT_AREA_SIZE kernel parameter is increased. The default is 64K - a very low figure. Increasing this to 1MB will have a very significant effect - by doing this index-creation times reduce by a factor of 10 . However note the specified amount of memory will be used by EVERY process connecting, so great care should be taken with this parameter if the database is shared with many other users. It might be possible to increase it just for index creation, then reduce it later.
Subscribe to:
Posts (Atom)